table des matières
Opérations de calcul statistique de base
Modification des valeurs des données statistiques
Sélection des valeurs de données pour le calcul statistique
Effectuer des calculs statistiques à une variable
Dessiner un graphique de régression
Dessiner un histogramme
Dessiner un diagramme en boîte et moustaches
Dessiner un graphique circulaire
Opérations de nuage de points
Effectuer un Test Z à un échantillon
Calculs statistiques et graphiques
Opérations de calcul statistique de base
- Pour saisir des valeurs dans une Donnée Statistique note adhésive.
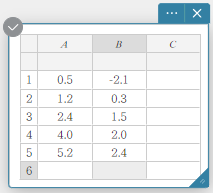
Dans l’exemple présenté dans cette section, les valeurs des données du tableau ci-dessous sont saisies dans les cellules A1 à B5 d’une note adhésive de données statistiques.
| A | B | |
|---|---|---|
| 1 | \(0.5\) | \(-2.1\) |
| 2 | \(1.2\) | \(0.3\) |
| 3 | \(2.4\) | \(1.5\) |
| 4 | \(4.0\) | \(2.0\) |
| 5 | \(5.2\) | \(2.4\) |
- Cliquez sur
 dans le menu note adhésive.
dans le menu note adhésive.

Cela affiche une note adhésive de données statistiques.

La cellule A1 est sélectionnée pour la saisie à ce moment-là. - Entrez \(0.5\) dans la cellule A1, puis appuyez sur [Entrée].
La cellule A2 est sélectionnée pour la saisie. - Entrez \(1.2\) dans la cellule A2, puis appuyez sur [Entrée].
La cellule A3 est sélectionnée pour la saisie. De même, saisissez les données jusqu’à la cellule A5. - Cliquez sur la cellule B1.
La cellule B1 est sélectionnée pour la saisie. - Entrez \(-2.1\) dans la cellule B1, puis appuyez sur [Entrée].
La cellule B2 est sélectionnée pour la saisie. La colonne C est également créée à ce stade (voir NOTE ci-dessous). - Entrez \(0.3\) dans la cellule B2, puis appuyez sur [Entrée].
La cellule B3 est sélectionnée pour la saisie. De même, saisissez les données jusqu’à la cellule B5.
NOTE
La saisie d’une valeur dans la colonne la plus à droite ajoute automatiquement une nouvelle colonne à sa droite.
Les cellules sous les étiquettes de colonne (A, B, C,…) peuvent être utilisées pour saisir un nom de liste pour chaque colonne. Pour plus de détails, voir “Attribution d’un nom à une liste”.
- Sélection des valeurs de données pour le calcul statistique
- Utilisez la procédure sous “Saisie de valeurs dans des données statistiques Note Adhésive” pour saisir les valeurs des données.
A B 1 \(0.5\) \(-2.1\) 2 \(1.2\) \(0.3\) 3 \(2.4\) \(1.5\) 4 \(4.0\) \(2.0\) 5 \(5.2\) \(2.4\) - Utilisez la souris de votre ordinateur pour faire glisser la cellule A1 vers la cellule B5
Ceci sélectionne la plage de cellules de la cellule A1 à la cellule B5.
NOTE
Vous pouvez sélectionner une colonne entière en cliquant sur son numéro de colonne.
Vous pouvez sélectionner une ligne entière en cliquant sur son numéro de ligne.
Vous pouvez cliquer ou faire glisser sur les numéros de colonne et utiliser les données de ces colonnes pour dessiner un graphique.
Dans ce cas, après avoir dessiné le graphique, vous pouvez également utiliser la liste déroulante du Graphique note adhésive pour sélectionner d’autres numéros de colonnes et redessiner le graphique.
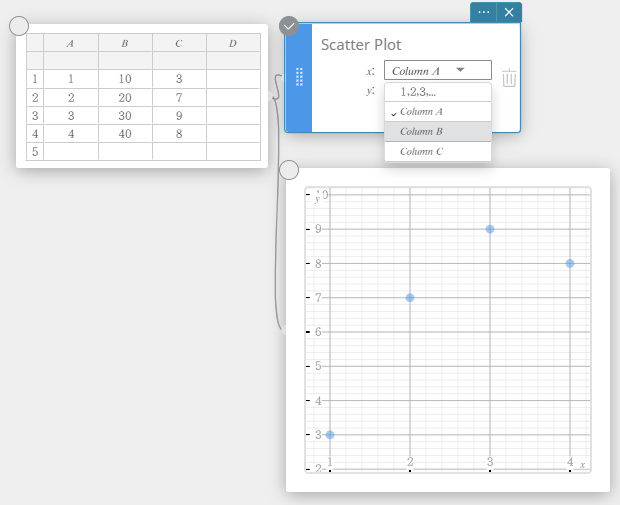
- Effectuer des calculs statistiques
Dans cet exemple, nous effectuons des calculs statistiques à deux variables et dessinons un nuage de points et un graphique de régression linéaire.
- Entrez les valeurs des données dans le tableau ci-dessous, puis sélectionnez toutes les données.
A B 1 \(0.5\) \(-2.1\) 2 \(1.2\) \(0.3\) 3 \(2.4\) \(1.5\) 4 \(4.0\) \(2.0\) 5 \(5.2\) \(2.4\) 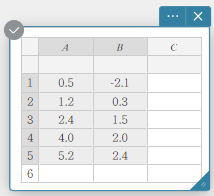
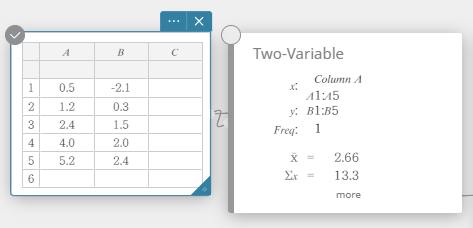
- Sur le clavier du logiciel, cliquez sur [Calcul] – [Deux variables].

Cela affiche les résultats du calcul statistique à deux variables.
- Cliquez sur
 sur le clavier du logiciel.
sur le clavier du logiciel.
- Sur le clavier du logiciel, cliquez sur [Graph] – [Scatter Plot].

Cela crée un nuage de points note adhésive et dessine simultanément un nuage de points sur le graphique note adhésive.
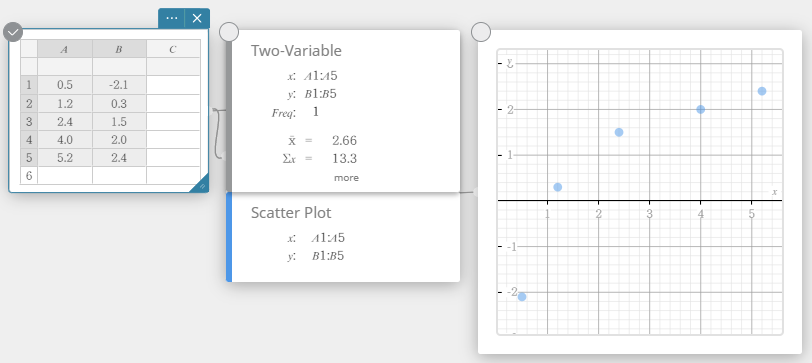
- Cliquez sur sur le clavier du logiciel.
- Sur le clavier du logiciel, cliquez sur [Régression] – [Régression linéaire].

Cela crée une Régression Linéaire note adhésive et dessine simultanément un graphe de régression linéaire sur le Graph note adhésive.
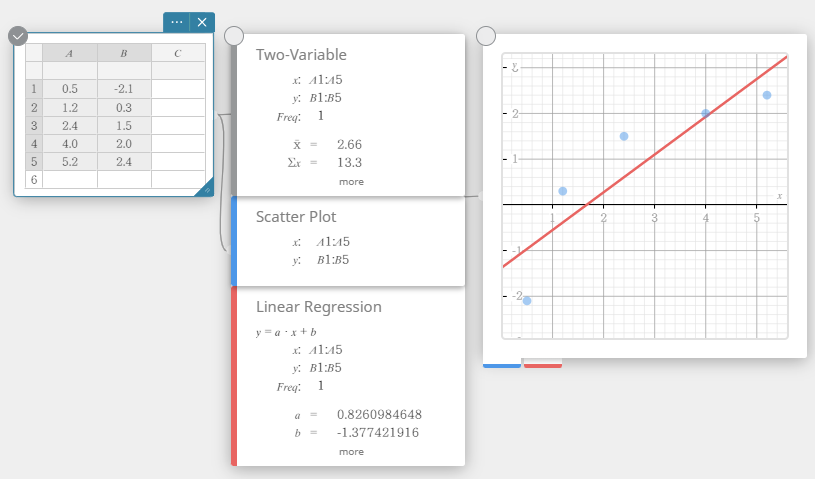
Modification des valeurs des données statistiques
- Pour corriger les valeurs des données
- Cliquez sur la cellule contenant la valeur de données que vous souhaitez corriger.
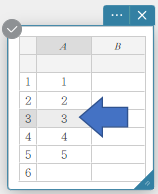
- Saisissez la nouvelle valeur des données, puis appuyez sur [Entrée].

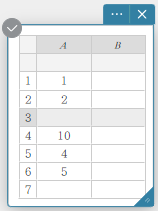
- Pour insérer une ligne
- Cliquez avec le bouton droit sur le numéro de la ligne dans laquelle vous souhaitez insérer une nouvelle ligne.
Cela affiche un menu.
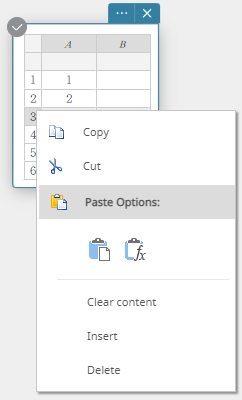
- Cliquez sur [Insérer].
Cela insère une ligne.
- Pour insérer une colonne
- Cliquez avec le bouton droit sur l’en-tête de la colonne dans laquelle vous souhaitez insérer une nouvelle colonne.
Cela affiche un menu.
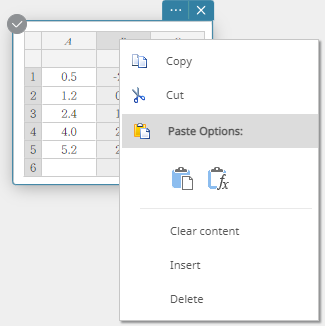
- Cliquez sur [Insérer].
Cela insère une colonne.
- Pour supprimer une ligne
- Cliquez avec le bouton droit sur le numéro de la ligne que vous souhaitez supprimer.
Cela affiche un menu.
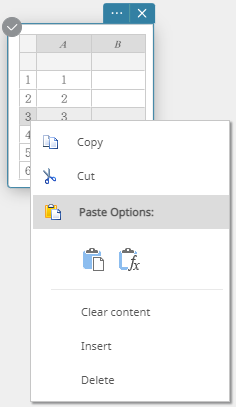
- Cliquez sur [Supprimer].
Cela supprime la ligne.
- Pour supprimer une colonne
- Cliquez avec le bouton droit sur l’en-tête de la colonne que vous souhaitez supprimer.
Cela affiche un menu.
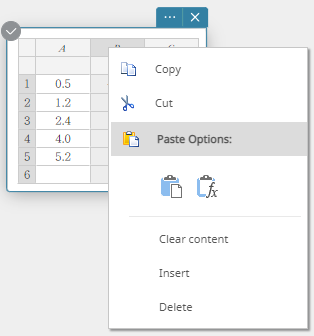
- Cliquez sur [Supprimer].
Cela supprime la colonne.
- Attribuer un nom à une liste
Une fois que vous avez attribué un nom à une liste, vous pouvez utiliser ce nom dans des tests et autres calculs statistiques. Les noms de liste sont saisis dans les cellules situées sous les noms de colonnes.
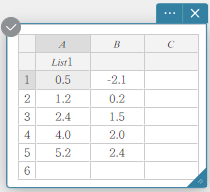
Exemple : Pour attribuer le nom “Liste1” à la colonne A
- Double-cliquez sur la cellule sous A.
Ceci sélectionne la cellule pour la saisie du nom de la liste.
- Entrez le nom de la liste “Liste1” , puis appuyez sur [Entrée].
Cela attribue “Liste1” comme nom de liste de la colonne A.
NOTE
Les règles suivantes s’appliquent aux noms de liste.
- Les noms de liste peuvent comporter jusqu’à 8 octets.
- Les caractères suivants sont autorisés dans un nom de liste : caractères majuscules et minuscules, caractères en indice, chiffres.
- les noms de liste sont sensibles à la casse. Par exemple, chacun des éléments suivants est traité comme un nom de liste différent : abc, Abc, aBc, ABC.
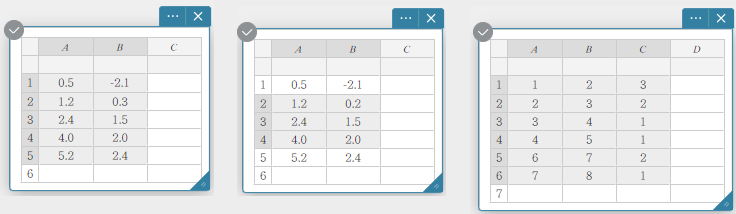
Sélection des valeurs de données pour le calcul statistique
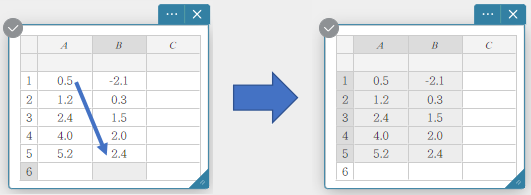
Vous pouvez sélectionner une plage de cellules en faisant glisser le pointeur de la souris dessus.
Exemples de sélection de données
NOTE
Vous pouvez sélectionner une colonne entière en cliquant sur son numéro de colonne.
Vous pouvez sélectionner une ligne entière en cliquant sur son numéro de ligne.
Des calculs statistiques peuvent être effectués si la plage de cellules sélectionnées comprend une ou plusieurs cellules vides.
Jusqu’à trois colonnes peuvent être utilisées pour les calculs statistiques. Les calculs statistiques ne peuvent pas être effectués si plus de trois colonnes sont sélectionnées.
Effectuer des calculs statistiques à une variable
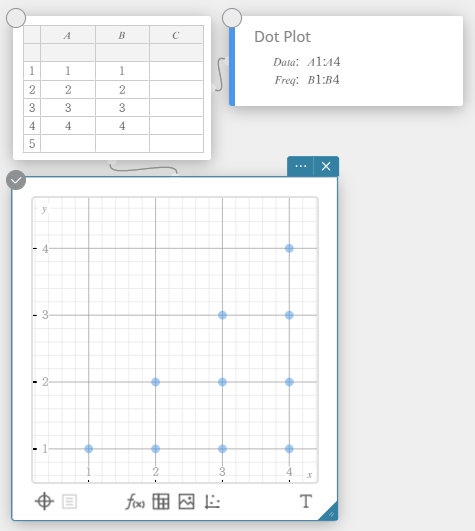
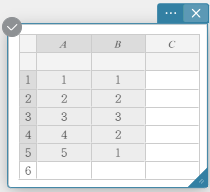
- Entrez les valeurs des données dans le tableau ci-dessous, avec les données dans la colonne A et la fréquence dans la colonne B.
Data Frequency \(1\) \(1\) \(2\) \(2\) \(3\) \(3\) \(4\) \(2\) \(5\) \(1\) - Faites glisser de la cellule A1 vers la cellule B5 pour sélectionner la plage de cellules entre elles.
- Sur le clavier du logiciel, cliquez sur [Calcul] – [Une variable].
Cela affiche les résultats du calcul statistique à une variable.
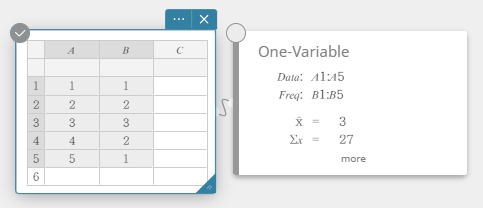
- Pour afficher d’autres éléments de résultat de calcul masqués, cliquez sur [plus] sur la note adhésive du calcul statistique.
Cela affiche les résultats de calcul masqués.
Pour remettre la note adhésive Calcul statistique dans sa configuration de taille réduite, cliquez sur [masquer].
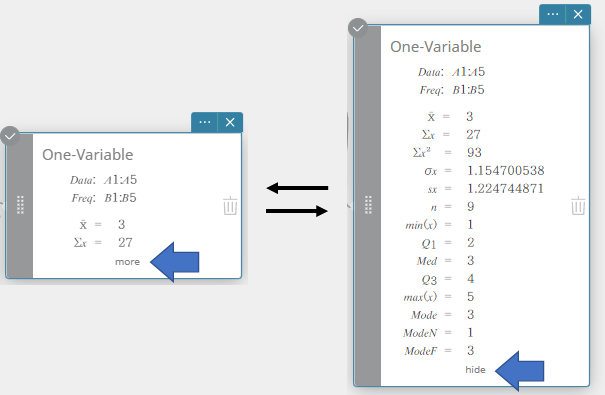
L’exécution d’un calcul statistique à une variable affiche les résultats ci-dessous.
\(\bar{\rm x}\) moyenne de l’échantillon
\(\Sigma {\rm x}\) somme de données
\(\Sigma {\rm x}^2\) somme des carrés
\(\sigma {\rm x}\) écart type de la population
\({\rm sx}\) écart type de l’échantillon
\({\rm n}\) taille de l’échantillon
\({\rm min(x)}\) le minimum
\({\rm Q}_1\) premier quartile
\({\rm Med}\) médian
\({\rm Q}_3\) troisième quartile
\({\rm max(x)}\) le maximum
\({\rm Mode}\) mode
\({\rm ModeN}\) nombre d’éléments du mode données
\({\rm ModeF}\) fréquence du mode données
Lorsque \({\rm Mode}\) propose plusieurs solutions, elles sont toutes affichées.
Dessiner un graphique de régression
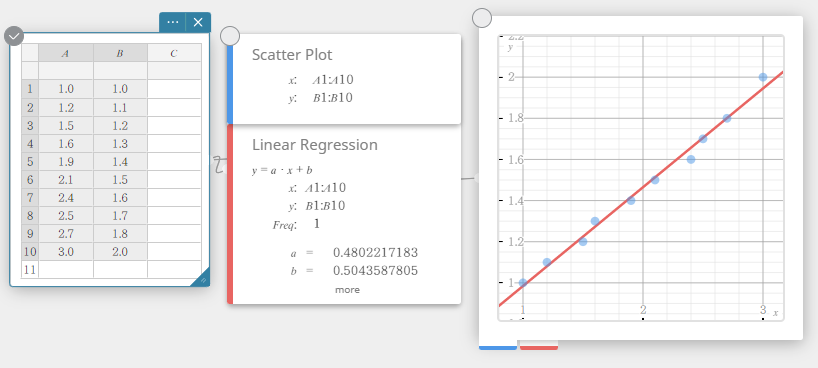
Dans cet exemple, nous utiliserons les valeurs de données ci-dessous pour dessiner un nuage de points, un graphique de régression linéaire et un graphique de régression quadratique.
- Entrez les valeurs des données dans le tableau ci-dessous, puis sélectionnez toutes les données.
A B \(1.0\) \(1.0\) \(1.2\) \(1.1\) \(1.5\) \(1.2\) \(1.6\) \(1.3\) \(1.9\) \(1.4\) \(2.1\) \(1.5\) \(2.4\) \(1.6\) \(2.5\) \(1.7\) \(2.7\) \(1.8\) \(3.0\) \(2.0\) 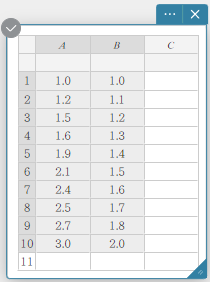
- Sur le clavier du logiciel, cliquez sur [Graph] – [Scatter Plot].

Cela crée un nuage de points note adhésive et dessine simultanément un nuage de points sur le graphique note adhésive.
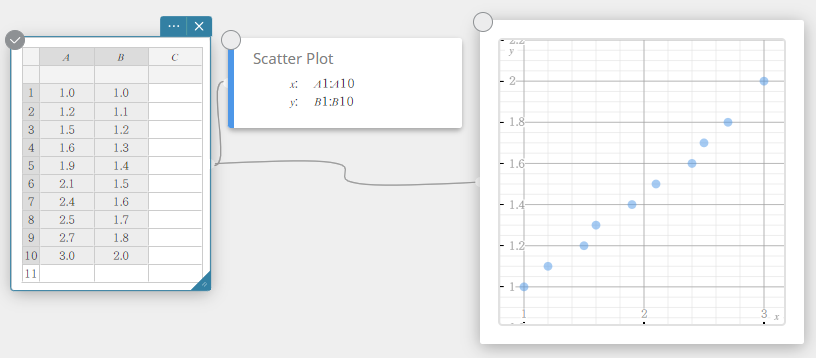
- Cliquez sur sur le clavier du logiciel.
- Sur le clavier du logiciel, cliquez sur [Régression] – [Régression linéaire].

Cela crée une Régression Quadratique note adhésive et dessine simultanément un graphe de régression quadratique sur le Graph note adhésive.
- Sur le clavier du logiciel, cliquez sur [Régression quadratique].

Cela crée une Régression Quadratique note adhésive et dessine simultanément un graphe de régression quadratique sur le Graph note adhésive.
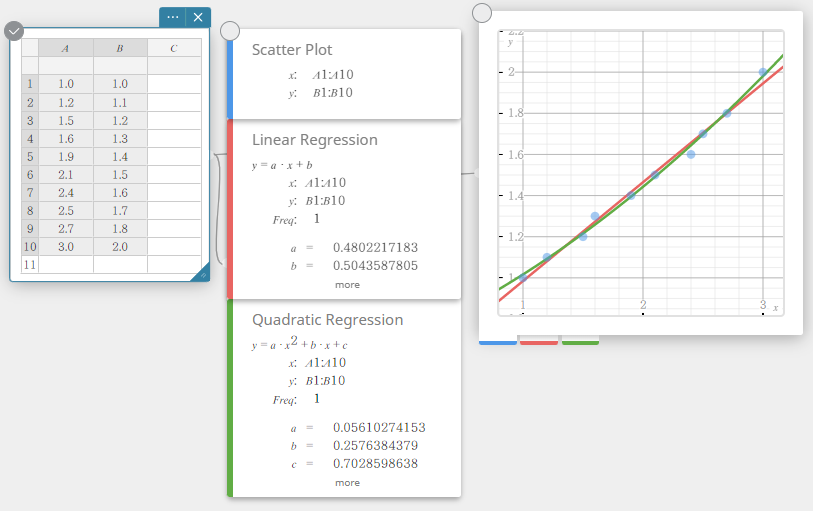
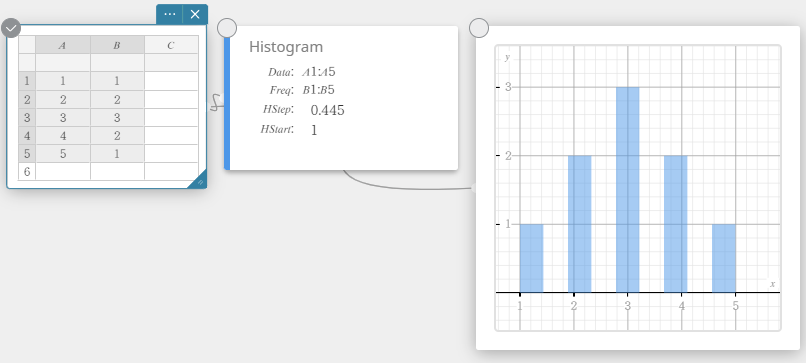
Dessiner un histogramme
- Entrez les valeurs des données dans le tableau ci-dessous, avec les données dans la colonne A et la fréquence dans la colonne B.
Data Frequency \(1\) \(1\) \(2\) \(2\) \(3\) \(3\) \(4\) \(2\) \(5\) \(1\) - Faites glisser de la cellule A1 vers la cellule B5 pour sélectionner la plage de cellules entre elles.
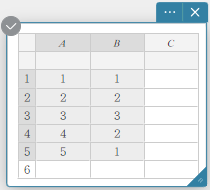
- Sur le clavier du logiciel, cliquez sur [Graphique] – [Histogramme].
Cela crée un Histogramme note adhésive et dessine simultanément un histogramme sur le Graphe note adhésive.
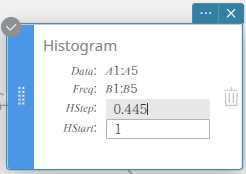
NOTE
Vous pouvez modifier la valeur de départ du tracé de l’histogramme (HStart) et la valeur de pas (HStep). Sur l’Histogramme note adhésive, cliquez sur HDémarrer ou HStep puis saisissez la valeur souhaitée.
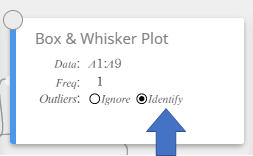
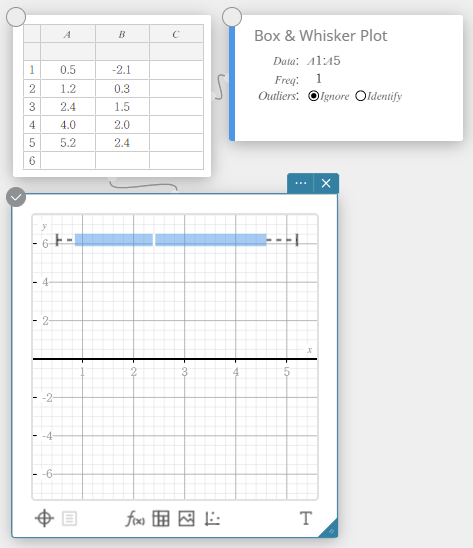
Dessiner un diagramme en boîte et moustaches
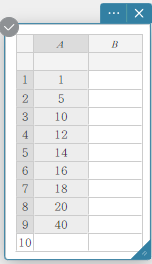
- Entrez les valeurs des données dans le tableau ci-dessous dans la colonne A.
A \(1\) \(5\) \(10\) \(12\) \(14\) \(16\) \(18\) \(20\) \(40\) - Faites glisser de la cellule A1 à la cellule A9 pour sélectionner la plage de cellules entre elles.
- Sur le clavier du logiciel, cliquez sur [Graph] – [Box & Whisker Plot].
Cela crée un diagramme en boîte et moustaches note adhésive et dessine simultanément un diagramme en boîte et moustaches sur le graphique note adhésive.
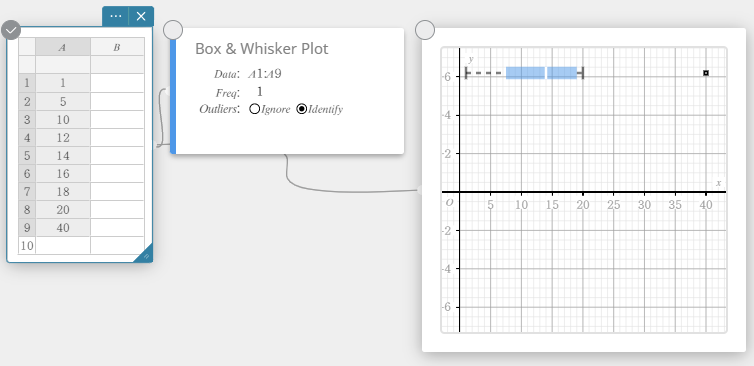
NOTE
Vous pouvez afficher les valeurs aberrantes. Pour ce faire, sélectionnez [Identifier] pour l’élément Outliers du Box & Whisker Plot vnote adhésive.
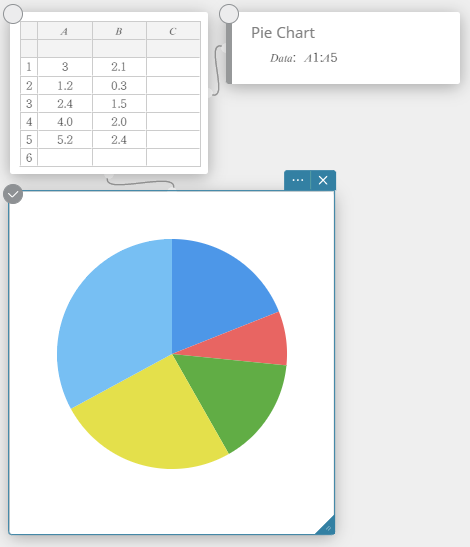
Dessiner un graphique circulaire
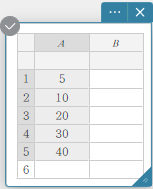
- Entrez les valeurs des données dans le tableau ci-dessous dans la colonne A.
A \(5\) \(10\) \(20\) \(30\) \(40\) - Faites glisser de la cellule A1 à la cellule A5 pour sélectionner la plage de cellules entre elles.
- Sur le clavier du logiciel, cliquez sur [Graphique] – [Camembert].
Cela crée un diagramme circulaire note adhésive et dessine simultanément un graphique circulaire sur une note adhésive*distincte.
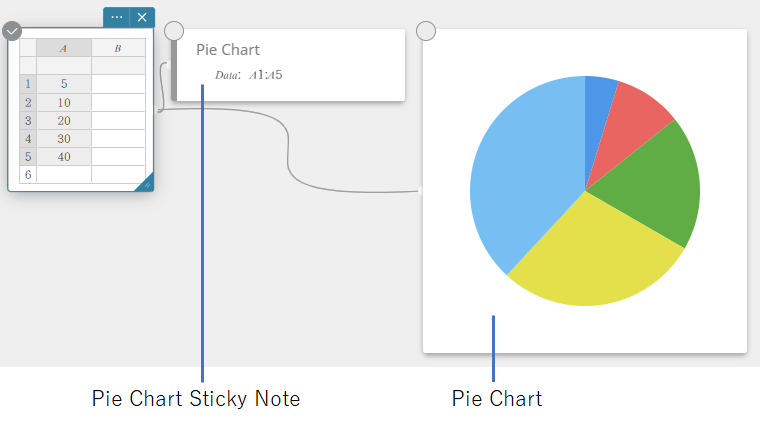
* Cela dessine le graphique sur le Graph note adhésif. Le type est différent lorsqu’un graphique circulaire est dessiné sur la note adhésive.
Opérations de nuage de points
- Pour déplacer les points d’un nuage de points
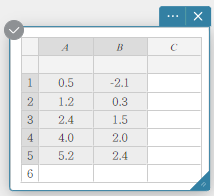
- Entrez les valeurs des données dans le tableau ci-dessous dans les colonnes A et B.
Data Frequency \(0.5\) \(-2.1\) \(1.2\) \(0.3\) \(2.4\) \(1.5\) \(4.0\) \(2.0\) \(5.2\) \(2.4\) - Faites glisser de la cellule A1 vers la cellule B5 pour sélectionner la plage de cellules entre elles.
- Sur le clavier du logiciel, cliquez sur [Graph] – [Scatter Plot].
Cela crée un nuage de points note adhésive et un graphique note adhésive, et dessine un nuage de points sur le graphique note adhésive.
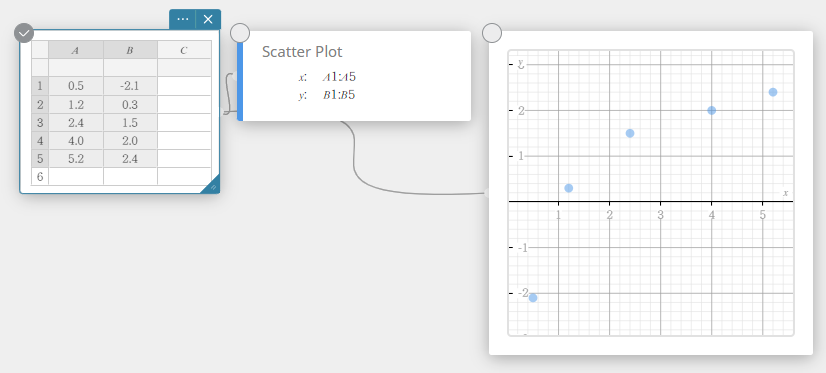
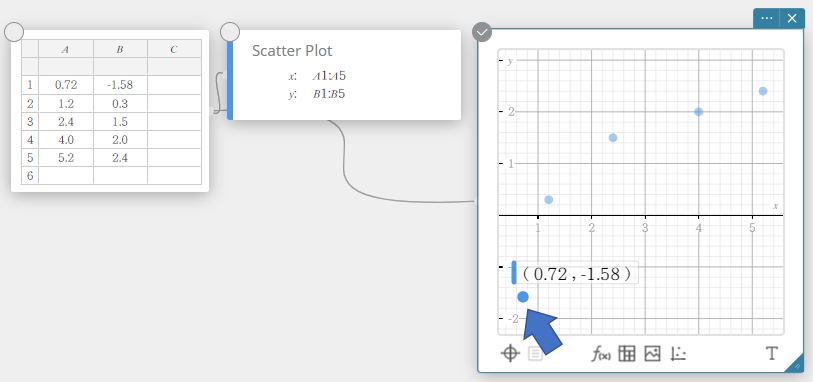
- Pour déplacer un point de nuage de points, faites-le glisser.
Cela modifiera également les valeurs des données statistiques note adhésive en coordonnées de la destination.
- Pour verrouiller une cellule
NOTE
Lorsqu’une cellule est verrouillée, sa valeur de données ne changera pas même si vous essayez de déplacer son point de nuage de points. Par exemple, si vous verrouillez une cellule de la colonne A, le point du nuage de points correspondant ne peut pas être déplacé le long de l’axe des x.
- Poursuivant la procédure sous « Pour déplacer les points d’un nuage de points », sélectionnez la cellule A1.
- Click
 sur la note adhésive du Calcul Statistique.
sur la note adhésive du Calcul Statistique.
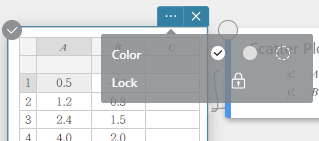
- Cliquez sur l’icône
 à côté de [Verrouiller].
à côté de [Verrouiller].
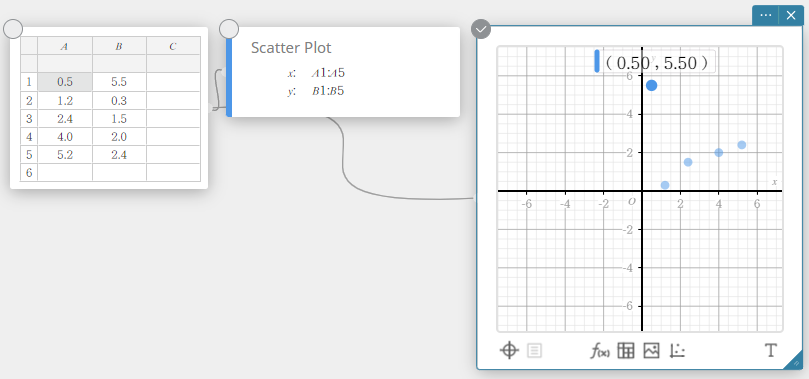
Cela verrouille les cellules A1. Si vous faites glisser le point du nuage de points qui correspond aux cellules A1 et B1, le mouvement ne sera pas possible le long de l’axe des x.
- Pour déverrouiller une cellule
- Sélectionnez la cellule verrouillée que vous souhaitez déverrouiller.
- Cliquez sur la note adhésive du Calcul Statistique.
- Cliquez sur l’icône
 à côté de [Déverrouiller].
à côté de [Déverrouiller].
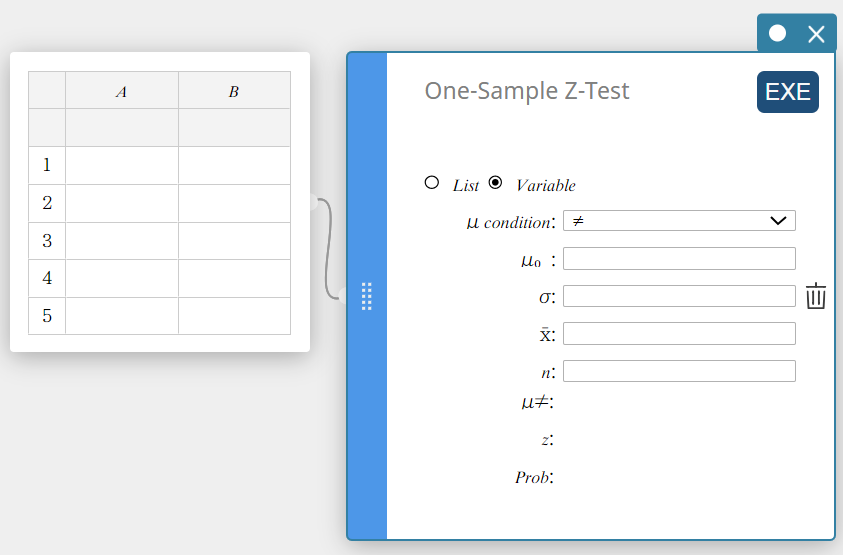
Effectuer un Test Z à un échantillon
- Pour préciser le nombre d’échantillons de données puis effectuer un Test Z à un échantillon

Exemple:
Taille de l’échantillon : n = 48
Moyenne de l’échantillon: \(\overline{x}=24.5\)
Hypothèse nulle: \(\mu \ne 0\)
Écart type: \(\sigma=3\)
- Créez une note adhésive de Données Statistiques.
- Sur le clavier du logiciel, cliquez sur [Test] – [Test Z à un échantillon].

Cela crée une Test Z à un échantillon note adhésive.
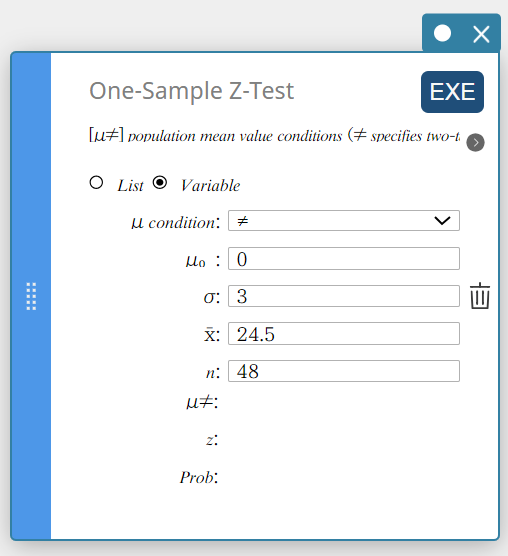
- Configurez les paramètres comme indiqué ci-dessDans le menu qui apparaît, sélectionnez “\(\ne\)”.
\(\mu_0\) : Entréet \(0\).
\(\sigma\): Entrée \(3\).
\(\overline{x}\) : Entrée \(24.5\).
\(n\) : Entrée \(48\).
- Cliquez sur [EXE].
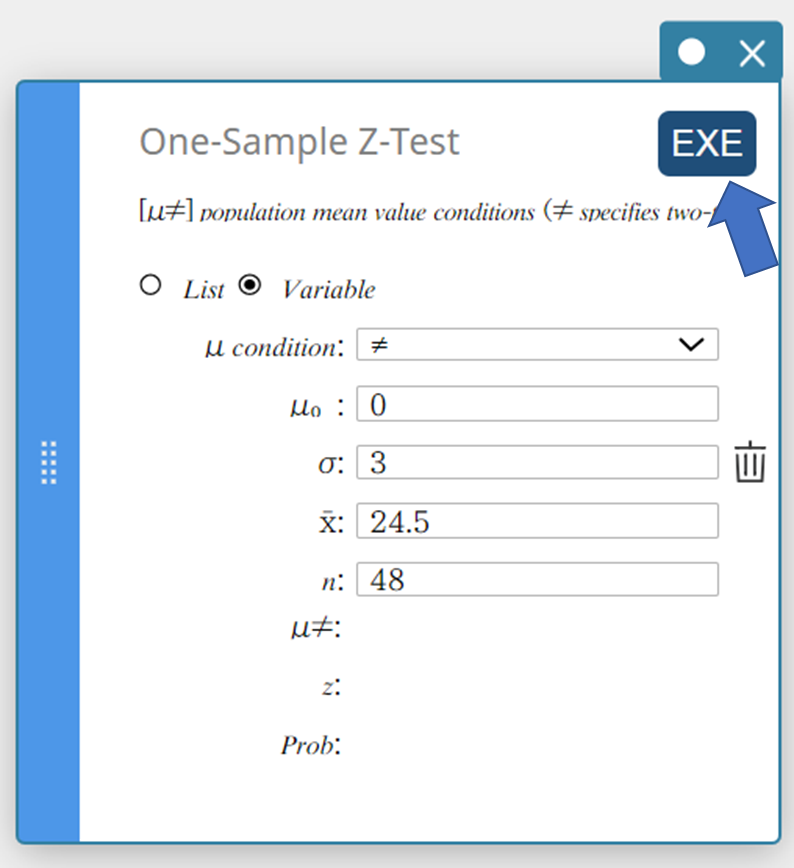
Cela affiche les résultats du calcul et le graphique.
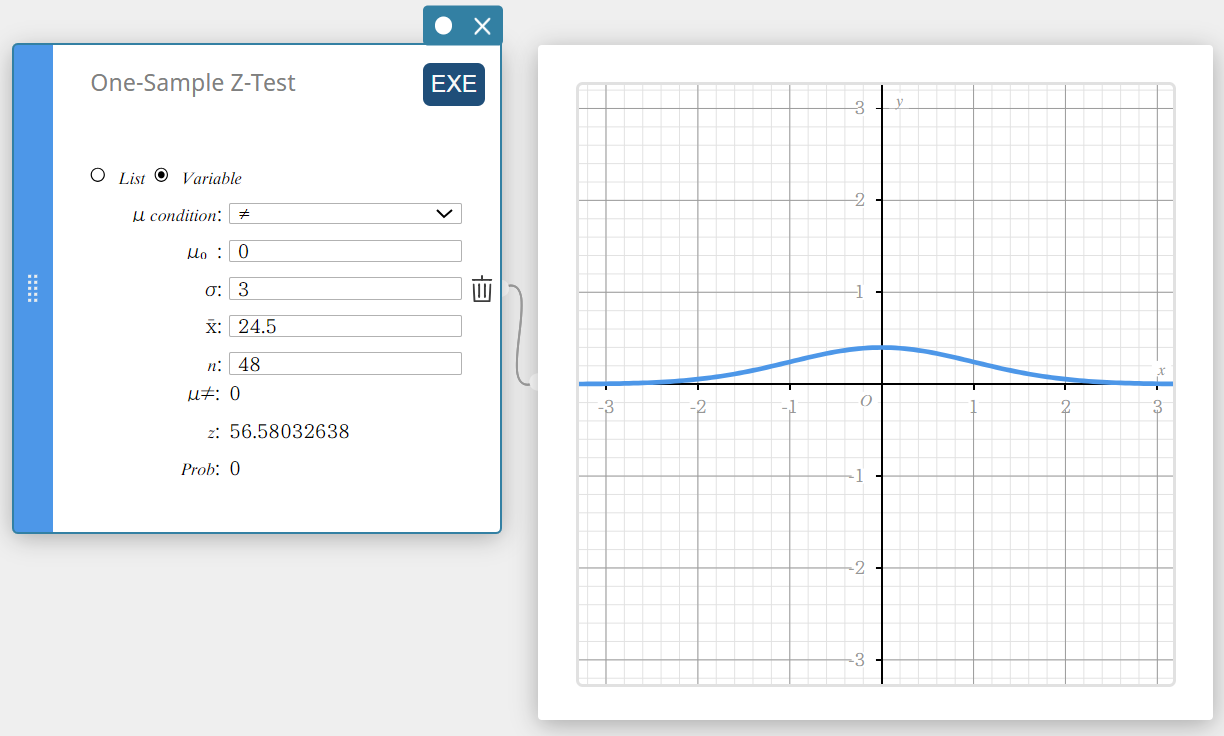
\(\mu \ne\) Condition de valeur moyenne de la population
\(\rm z\) Valeur
\(\rm p\) Valeur probable
\(\overline{x}\) Sample mean
\(n\) Sample size
- TPour utiliser des listes pour effectuer un Test Z à un échantillon
- Saisissez les noms de liste suivants : Liste 1 pour la colonne A, Liste 2 pour la colonne B.
- Saisissez la valeur des données dans le tableau ci-dessous.
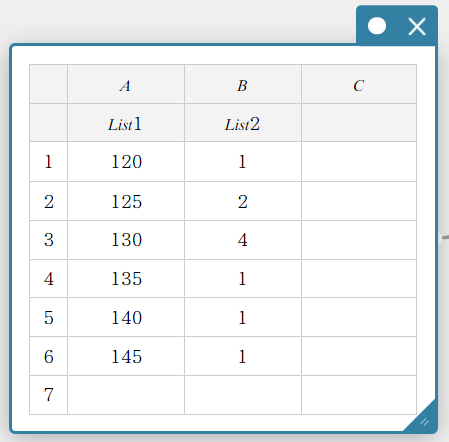
- Faites glisser de la cellule A1 vers la cellule B6 pour sélectionner la plage de cellules.
- Sur le clavier du logiciel, cliquez sur [Test] – [Test Z à un échantillon].

Cela crée une Test Z à un échantillon note adhésive.
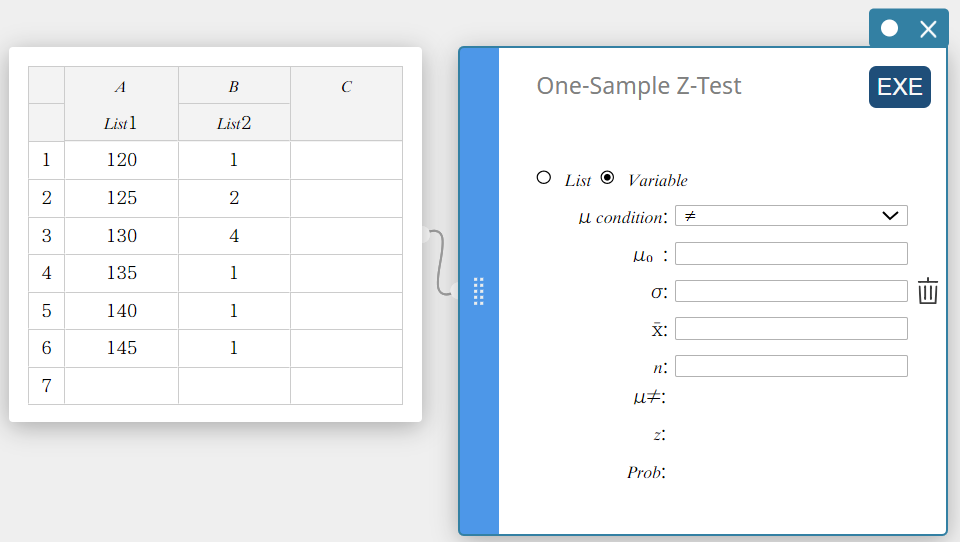
- Cliquez sur “Liste”.
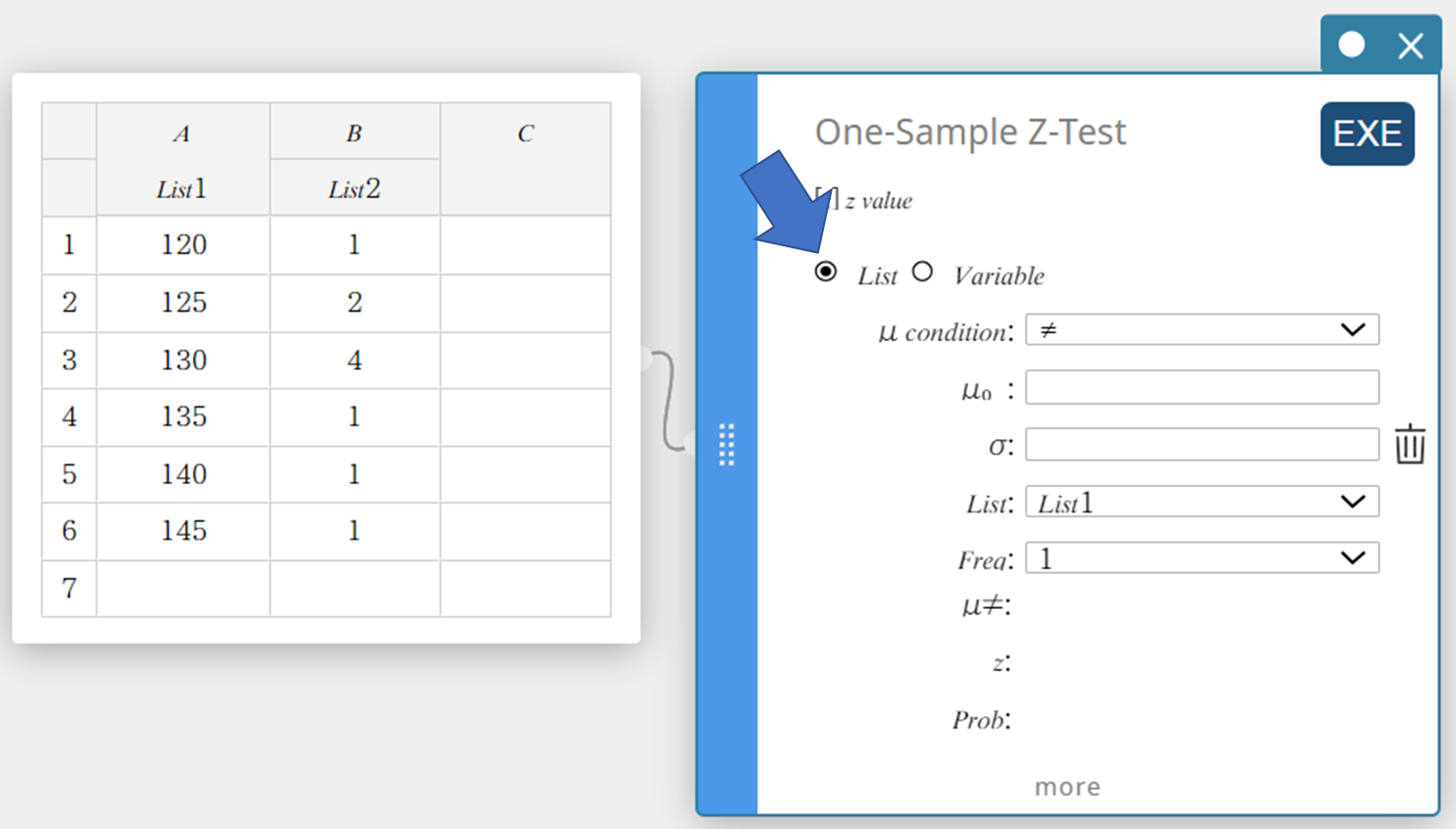
- Configurez les paramètres comme indiqué ci-dessous.
Condition\(\mu\): Dans le menu qui apparaît, sélectionnez “\(\gt\)”.
\(\mu_0\) : Entrée \(120\).
\(\sigma\): Entrée \(19\).
Liste: Dans le menu qui apparaît, sélectionnez “Liste1”.
Fréquence: Dans le menu qui apparaît, sélectionnez “Liste2”.
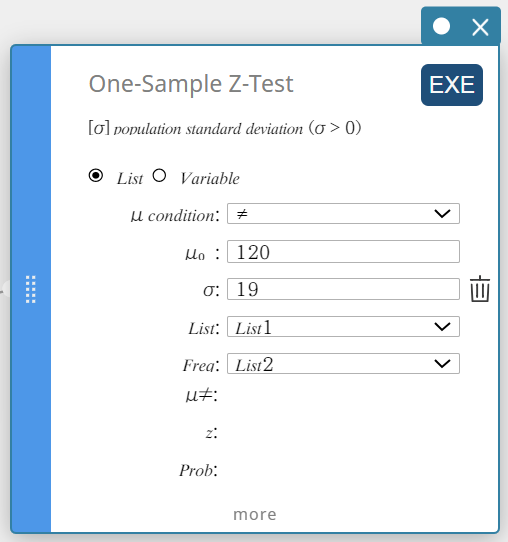
- Cliquez sur [EXE].
Cela affiche les résultats du calcul et le graphique.
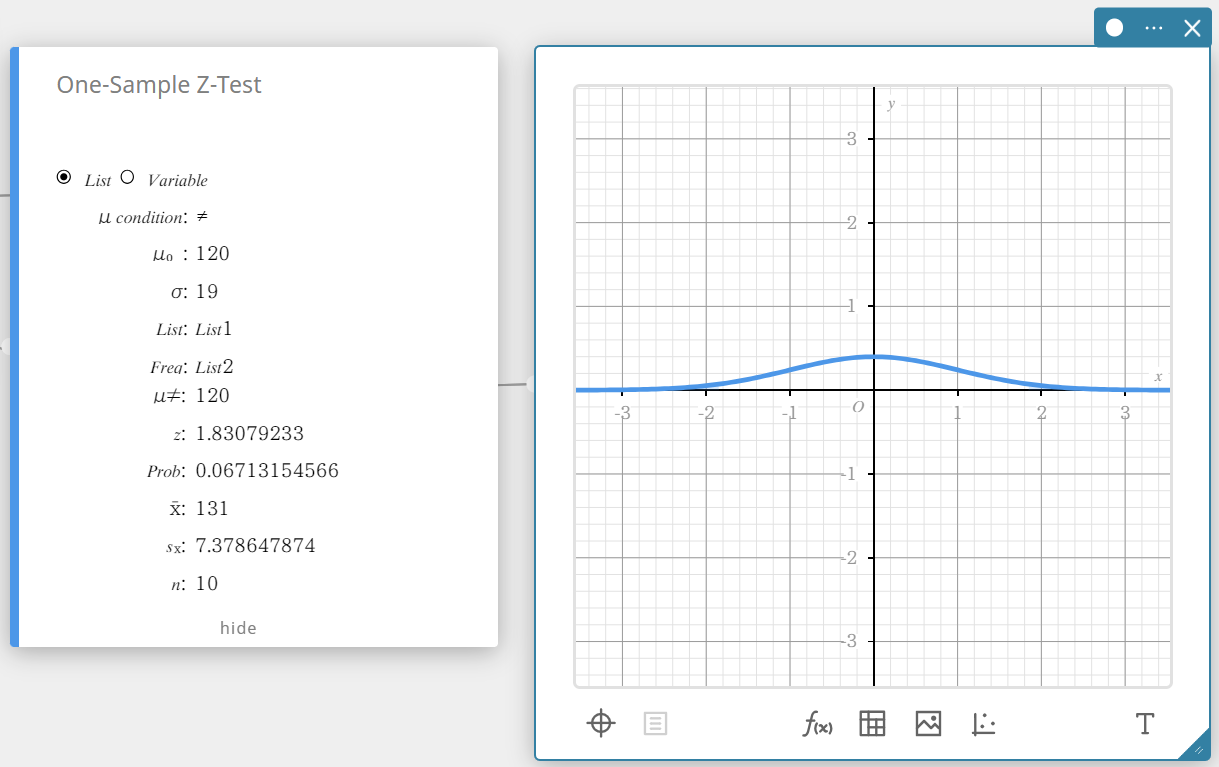
\(\mu \gt\)…condition de valeur moyenne de la population
\(\rm z\)…valeur \(\rm z\)
\(\rm p\)…valeur probable \(\rm p\)
\(\overline{x}\)…moyenne de l’échantillon
\({\rm Sx}\)…écart type de l’échantillon
\(n\)…taille de l’échantillon
Calculs statistiques et graphiques
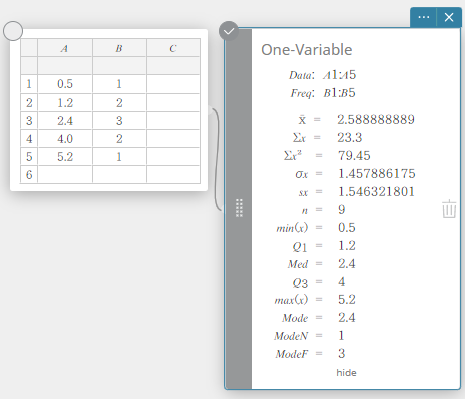
Calculs statistiques
Une variable
Ceci affiche les résultats du calcul des statistiques à une variable.
\(\bar{\rm x}\) … moyenne de l’échantillon
\(\Sigma {\rm x}\) … somme de données
\(\Sigma {\rm x}^2\) … somme des carrés
\(\sigma {\rm x}\) … écart type de la population
\({\rm sx}\) … écart type de l’échantillon
\({\rm n}\) … taille de l’échantillon
\({\rm min(x)}\) … le minimum
\({\rm Q}_1\) … premier quartile
\({\rm Med}\) … médian
\({\rm Q}_3\) … troisième quartile
\({\rm max(x)}\) … maximum
\({\rm Mode}\) … mode
\({\rm ModeN}\) … nombre d’éléments du mode données
\({\rm ModeF}\) … fréquence du mode données
\({\rm Mode}\) Lorsque Mode propose plusieurs solutions, elles sont toutes affichées.
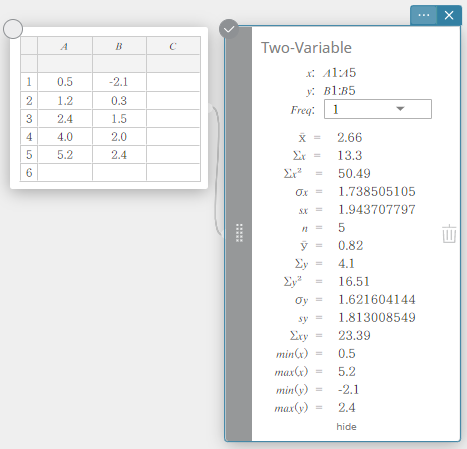
Deux variables
Ceci affiche les résultats du calcul des statistiques à variables appariées.
\(\bar{\rm x}\) … moyenne de l’échantillon
\(\Sigma {\rm x}\) … somme de données
\(\Sigma {\rm x}^2\) … somme des carrés
\(\sigma {\rm x}\) … écart type de la population
\({\rm sx}\) … sample standard deviation
\({\rm n}\) … taille de l’échantillon
\(\bar{\rm y}\) … moyenne de l’échantillon
\(\Sigma {\rm y}\) … somme de données
\(\Sigma {\rm y}^2\) … somme des carrés
\(\sigma {\rm y}\) … écart type de la population
\({\rm sy}\) … écart type de l’échantillon
\(\Sigma {\rm xy}\) … somme des produits XList et YList data
\({\rm minX}\) … le minimum
\({\rm maxX}\) … maximum
\({\rm minY}\)… le minimum
\({\rm maxY}\) … maximum
Calculs et graphiques de régression
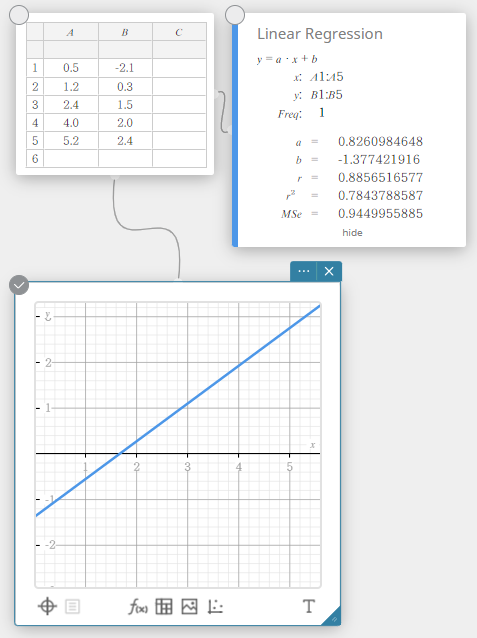
Régression linéaire
La régression linéaire utilise la méthode des moindres carrés pour déterminer l’équation qui correspond le mieux à vos points de données et renvoie les valeurs de la pente et de l’ordonnée à l’origine. La représentation graphique de cette relation est un graphique de régression linéaire.
\(y = a \cdot x + b\)
\(a\) … coefficient de régression (pente)
\(b\) … terme constant de régression (ordonnée à l’origine)
\(r\) … coefficient de corrélation
\(r^2\) … coefficient de détermination
\({\rm MSe}\) … erreur quadratique moyenne
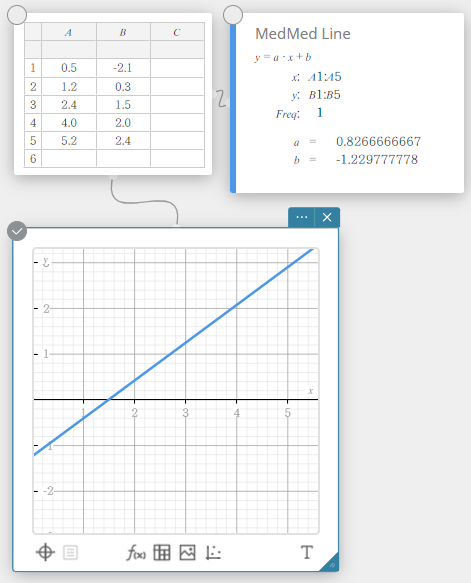
Régression Med-Med
Lorsque vous pensez que les données contiennent des valeurs extrêmes, vous devez utiliser le graphique Med-Med (basé sur les médianes) à la place du graphique de régression linéaire. Le graphique Med-Med est similaire au graphique de régression linéaire, mais il minimise également les effets des valeurs extrêmes.
\(y = a \cdot x + b\)
\(a\) … coefficient de régression (pente)
\(b\) … terme constant de régression (ordonnée à l’origine)
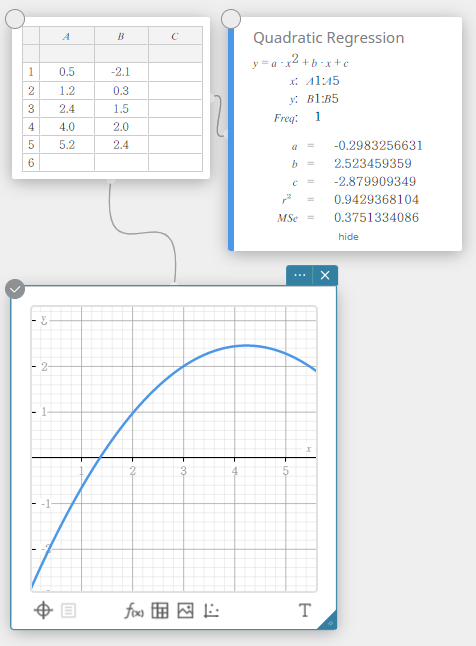
Régression quadratique
Le graphique de régression quadratique utilise la méthode des moindres carrés pour tracer une courbe qui passe à proximité d’autant de points de données que possible. Ce graphique peut être exprimé sous forme d’expression de régression quadratique.
\(y = a \cdot x^2 + b \cdot x + c\)
\(a\) … deuxième coefficient de régression
\(b\) … premier coefficient de régression
\(c\) … terme constant de régression (ordonnée à l’origine)
\(r^2\) … coefficient de détermination
\({\rm MSe}\) … erreur quadratique moyenne
Régression cubique
Le graphique de régression cubique utilise la méthode des moindres carrés pour tracer une courbe qui passe à proximité d’autant de points de données que possible. Ce graphique peut être exprimé sous forme d’expression de régression cubique.
\(y = a \cdot x^3 + b \cdot x^2 + c \cdot x + d\)
\(a\) … troisième coefficient de régression
\(b\) … deuxième coefficient de régression
\(c\) … premier coefficient de régression
\(d\) … terme constant de régression (ordonnée à l’origine)
\(r^2\) … coefficient de détermination
\({\rm MSe}\) … erreur quadratique moyenne
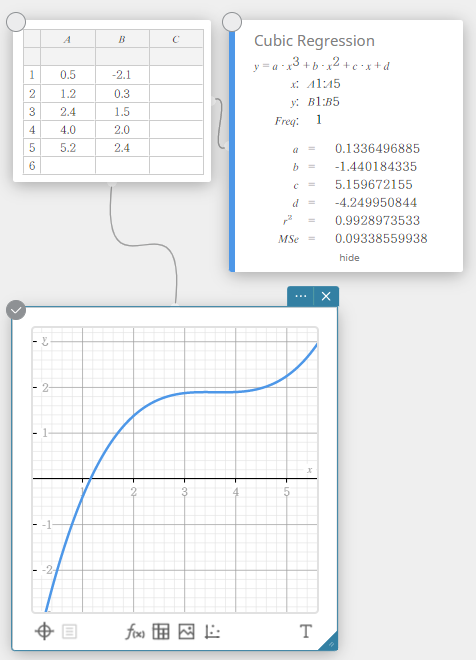
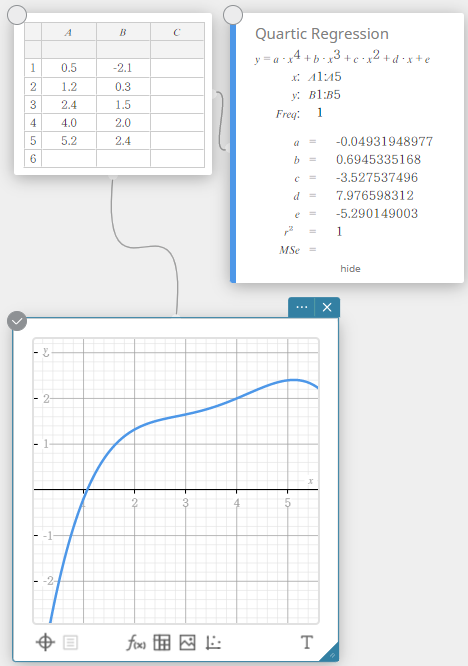
Régression quartique
Le graphique de régression quartique utilise la méthode des moindres carrés pour tracer une courbe qui passe à proximité d’autant de points de données que possible. Ce graphique peut être exprimé sous forme d’expression de régression quartique.
\(y = a \cdot x^4 + b \cdot x^3 + c \cdot x^2 + d \cdot x + e\)
\(a\) … quatrième coefficient de régression
\(b\) … troisième coefficient de régression
\(c\) … deuxième coefficient de régression
\(d\) … premier coefficient de régression
\(e\) … terme constant de régression (ordonnée à l’origine)
\(r^2\) … coefficient de détermination
\({\rm MSe}\) … erreur quadratique moyenne
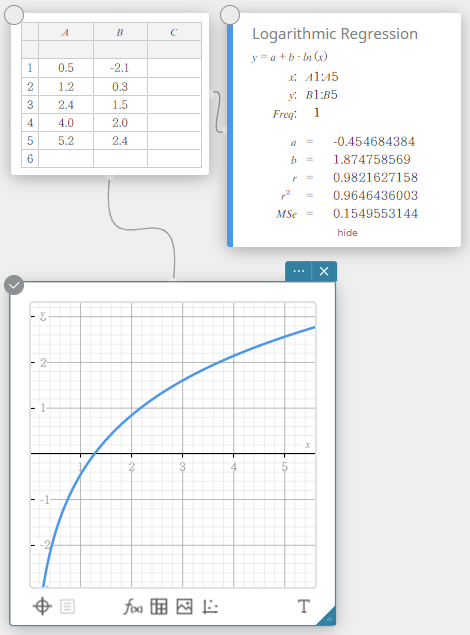
Régression logarithmique
La régression logarithmique exprime \(y\) comme une fonction logarithmique de \(x\). La formule de régression logarithmique normale est \(y=a+b \cdot \ln(x)\).Si nous disons que \(X=\ln(x)\), alors cette formule correspond à la formule de régression \(y=a+b \cdot X\).
\(y = a + b \cdot \ln(x)\)
\(a\) … terme constant de régression
\(b\) … coefficient de régression
\(r\) … coefficient de corrélation
\(r^2\) … coefficient de détermination
\({\rm MSe}\) … erreur quadratique moyenne
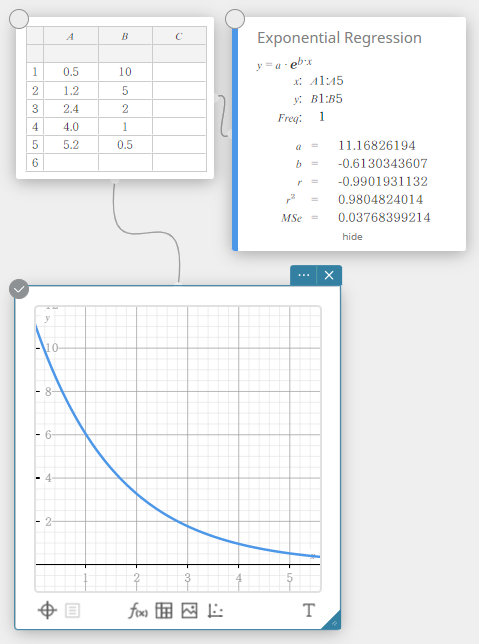
Régression exponentielle
La régression exponentielle peut être utilisée lorsque \(y\) est proportionnel à la fonction exponentielle de \(x\). La formule de régression exponentielle normale est \(y=a \cdot e^{b \cdot x}\). Si nous obtenons les logarithmes des deux côtés, nous obtenons \(\ln(y)=\ln(a)+b \cdot x\). Ensuite, si l’on dit que \(Y=\ln(y)\) et \(A=\ln(a)\), la formule correspond à la formule de régression linéaire \(Y=A+b \cdot x\).
\(y = a \cdot e^{b \cdot x}\)
\(a\) … coefficient de régression
\(b\) … terme constant de régression
\(r\) … coefficient de corrélation
\(r^2\) … coefficient de détermination
\({\rm MSe}\) … erreur quadratique moyenne
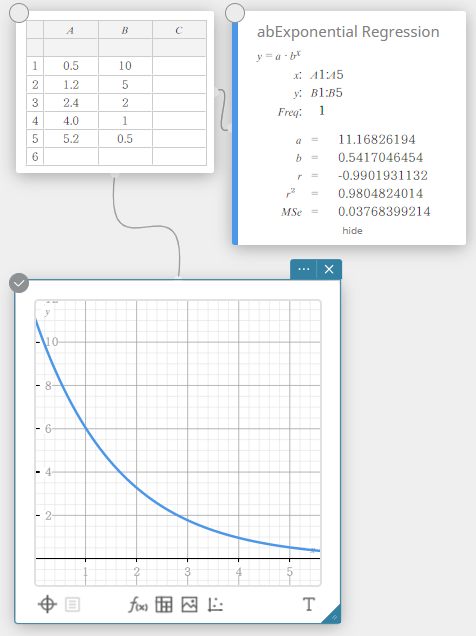
abRégression exponentielle
La régression exponentielle peut être utilisée lorsque \(y\) est proportionnel à la fonction exponentielle de \(x\). La formule de régression exponentielle normale dans ce cas est \(y=a \cdot b^x\). Si nous prenons les logarithmes naturels des deux côtés, nous obtenons \(\ln(y)=\ln(a)+(\ln(b)) \cdot x\). Ensuite, si l’on dit que \(Y=\ln(y)\), \(A=\ln(a)\) et \(B=\ln(b)\), la formule correspond à la formule de régression linéaire \(Y=A+B \cdot x\).
\(y = a \cdot b^x\)
\(a\) … terme constant de régression
\(b\) … coefficient de régression
\(r\) … coefficient de corrélation
\(r^2\) … coefficient de détermination
\({\rm MSe}\) … erreur quadratique moyenne
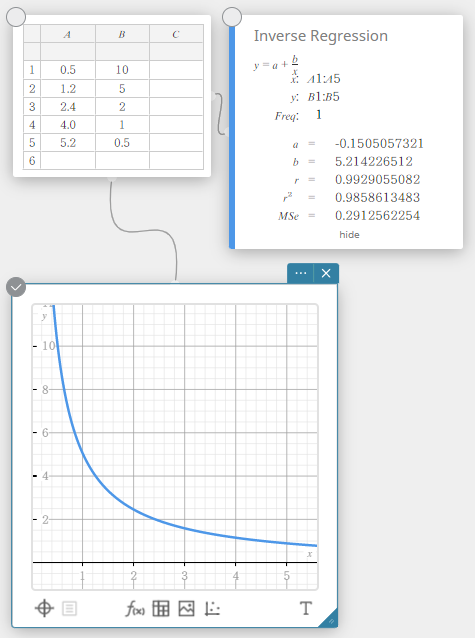
Régression inverse
La régression inverse exprime \(y\) comme une fonction inverse de \(x\). La formule de régression inverse normale est \(y=a+b/x\). Si nous disons que \(X=1/x\), alors cette formule correspond à la formule de régression linéaire \(y=a+b・X\).
\(y=a+b/x\)
\(a\) … terme constant de régression
\(b\) … Coefficient de régression
\(r\) …. Coefficient de corrélation
\(r^2\) … coefficient de détermination
\({\rm MSe}\) … erreur quadratique moyenne
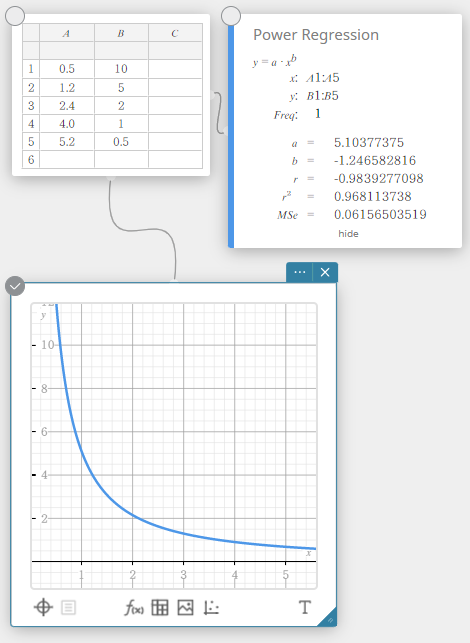
Régression de puissance
La régression de puissance peut être utilisée lorsque \(y\) est proportionnel à la puissance de \(x\). La formule normale de régression de puissance est \(y=a \cdot x^b\). Si nous obtenons les logarithmes naturels des deux côtés, nous obtenons \(\ln(y)=\ln(a)+b \cdot \ln(x)\). Ensuite, si nous disons que \(X=\ln(x)\), \(Y=\ln(y)\), and \(A=\ln(a)\), la formule correspond à la formule de régression linéaire \(Y=A+b \cdot X\).
\(y = a \cdot x^b\)
\(a\) … coefficient de régression
\(b\) … pouvoir de régression
\(r\) … coefficient de corrélation
\(r^2\) … coefficient de détermination
\({\rm MSe}\) … erreur quadratique moyenne
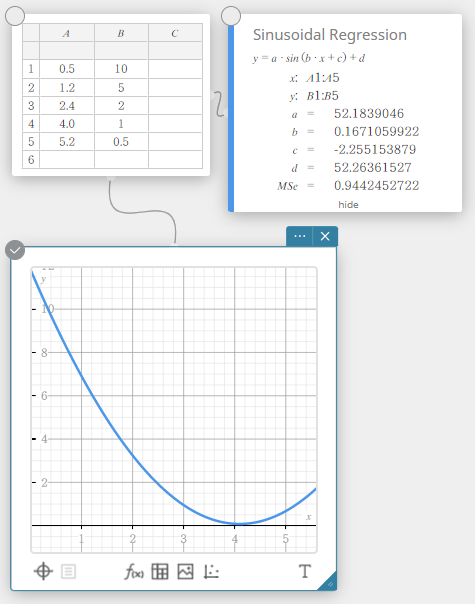
Régression sinusoïdale
La régression sinusoïdale est la meilleure solution pour les données qui se répètent à un intervalle fixe régulier dans le temps.
\(y = a \cdot \sin( b \cdot x + c ) + d\)
\(a\), \(b\), \(c\), \(d\) … coefficient de régression
\({\rm MSe}\) … erreur quadratique moyenne
Régression logistique
La régression logistique est la meilleure pour les données dont les valeurs augmentent continuellement avec le temps, jusqu’à ce qu’un point de saturation soit atteint.
\(\displaystyle y=\frac{c}{1+a \cdot e^{-b \cdot x}}\)
\(a\), \(b\), \(c\) … coefficient de régression
\({\rm MSe}\) … erreur quadratique moyenne
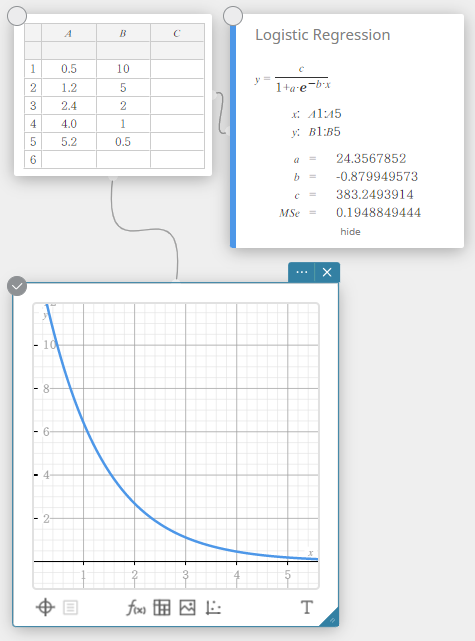
Essais
Test Z à un échantillon
Teste la moyenne d’un échantillon unique par rapport à la moyenne connue de l’hypothèse nulle lorsque l’écart type de la population est connu. La distribution normale est utilisée pour le test Z à un échantillon.
\(Z=\displaystyle \frac{\overline{x}-\mu_{0}}{\displaystyle \frac{\sigma}{\sqrt{n}}}\)
\(\overline{x}\) : moyenne de l’échantillon
\(\mu_{0}\) : moyenne de écart type de la population
\(\sigma\) : écart type de la population
\(n\) : taille de l’échantillon
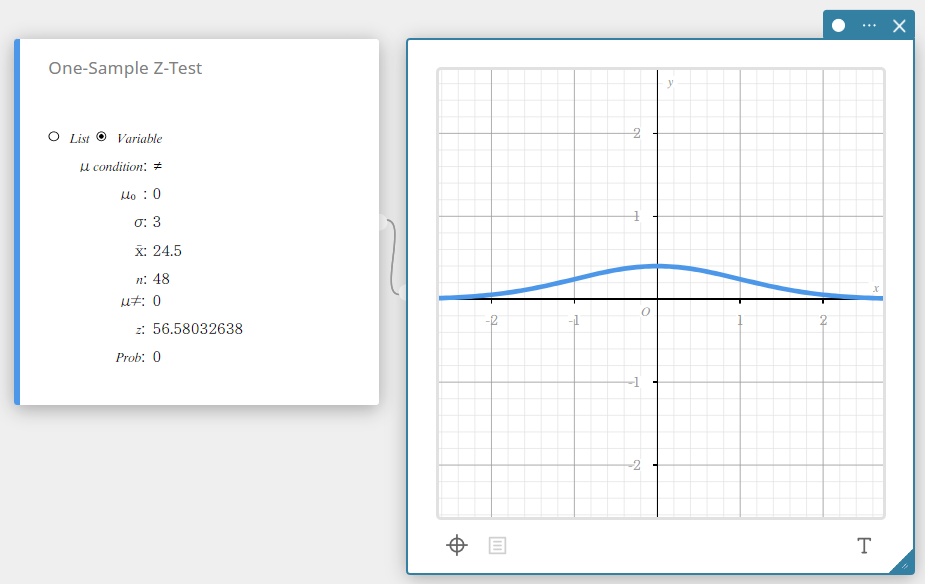
Type de données : Variable
- Termes d’entrée
\( \mu \) condition : conditions de test de la valeur moyenne de la population (“\(\neq\)” spécifie un test bilatéral, “<” spécifie un test unilatéral inférieur, “>” spécifie un test unilatéral supérieur.)
\( \mu_{0} \) : moyenne de population supposée
\( \sigma \) : écart type de la population(\( \sigma > 0 \))
\(\overline{x}\) : moyenne de l’échantillon
\(n\) : taille de l’échantillon (entier positif) -
Conditions de sortie
\( \mu \neq \) : condition de valeur moyenne de la population
\(z\) : z valeur
Prob : \(p\) valeur
Type de données : Liste
- Termes d’entrée
\( \mu \) Conditions de test de la valeur moyenne de la population (“\(\neq\)” spécifie un test bilatéral, “<” spécifie un test unilatéral inférieur, “>” spécifie un test unilatéral supérieur.)
\( \mu_{0} \) : moyenne de population supposée
\( \sigma \) : écart type de la population (\( \sigma > 0 \))
Liste : liste de données
Freq : fréquence (1 ou nom de la liste) -
Conditions de sortie
\( \mu \neq \) : condition de valeur moyenne de la population
\(z\) : \(z\) valeur
Prob : \(p\) valeur
\( \overline{x} \) : moyenne de l’échantillon
\( s_{x} \) : écart type de l’échantillon
\( n \) : taille de l’échantillon
Test Z à deux échantillons
Teste la différence entre deux moyennes lorsque les écarts types des deux populations sont connus. La distribution normale est utilisée pour le test Z à deux échantillons.
\( Z=\displaystyle \frac{ \overline{x}_{1} – \overline{x}_{2} }{ \sqrt{\displaystyle \frac{{\sigma_{1}}^2}{n_{1}} +\displaystyle \frac{{\sigma_{2}}^2}{n_{2}} } } \)
\( \overline{x}_{1} \) : moyenne de l’échantillon des données de l’échantillon 1
\( \overline{x}_{2} \) : moyenne de l’échantillon des données de l’échantillon 2
\( \sigma_{1} \) : écart type de la population de l’échantillon 1
\( \sigma_{2} \) : écart type de la population de l’échantillon 2
\( n_{1} \) : taille de l’échantillon 1
\( n_{2} \) : taille de l’échantillon 2
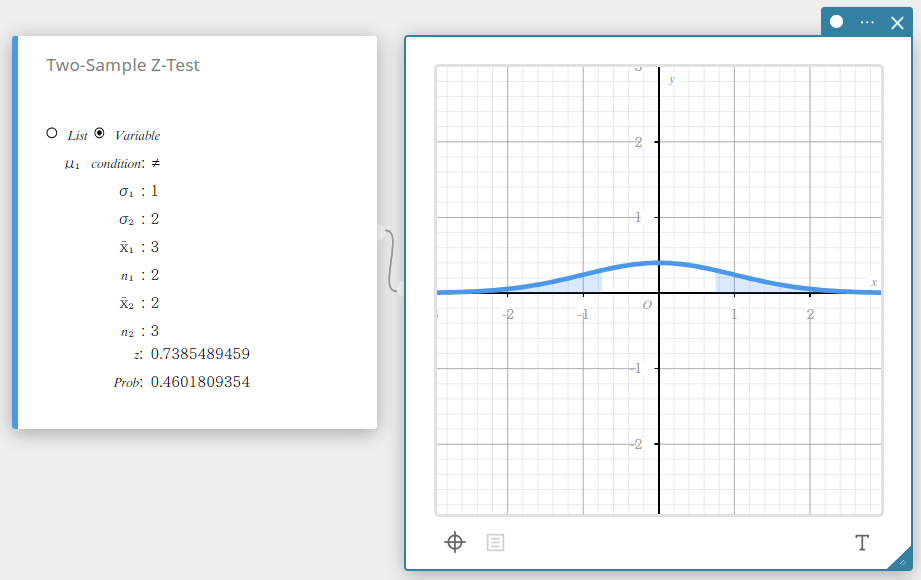
Type de données : Variable
- Termes d’entrée
\( \mu_{1} \) condition : conditions de test de la valeur moyenne de la population (“\(\neq\)” spécifie un test bilatéral, “<” spécifie un test unilatéral où l’échantillon 1 est inférieur à l’échantillon 2, “>” spécifie un test unilatéral où l’échantillon 1 est supérieur à l’échantillon 2).
\( \sigma_{1} \) : écart type de la population de l’échantillon 1 (\( \sigma_{1} > 0 \))
\( \sigma_{2} \) : écart type de la population de l’échantillon 2(\( \sigma_{2} > 0 \))
\( \overline{x}_{1} \) : moyenne de l’échantillon des données de l’échantillon 1
\( n_{1} \) :taille de l’échantillon 1 (entier positif)(positive integer)
\( \overline{x}_{2} \) : moyenne de l’échantillon des données de l’échantillon 2
\( n_{2} \) : moyenne de l’échantillon des données de l’échantillon 2 -
Conditions de sortie
\(z\) : z valeur
Prob : \(p\) valeur
Type de données : Liste
- Input Terms
\( \mu_{1} \) condition : conditions de test de la valeur moyenne de la population (“\(\neq\)” spécifie un test bilatéral, “<” spécifie un test unilatéral où l’échantillon 1 est inférieur à l’échantillon 2, “>” spécifie un test unilatéral où l’échantillon 1 est supérieur à l’échantillon 2).
\( \sigma_{1} \) : écart type de la population de l’échantillon 1(\( \sigma_{1} > 0 \))
\( \sigma_{2} \) : écart type de la population de l’échantillon 2(\( \sigma_{2} > 0 \))
List(1) : liste où se trouvent les données de l’échantillon 1
List(2) : liste où se trouvent les données de l’échantillon 2
Freq(1) : fréquence de l’échantillon 1 (1 ou nom de la liste)
Freq(2) : fréquence de l’échantillon 2 (1 ou nom de la liste) -
Conditions de sortie
\(z\) : z valeur
Prob : \(p\) valeur
\( \overline{x}_{1} \) : moyenne de l’échantillon des données de l’échantillon 1
\( \overline{x}_{2} \) : moyenne de l’échantillon des données de l’échantillon 2
\( s_{x_{1}} \) : écart type de l’échantillon 1
\( s_{x_{2}} \) : écart type de l’échantillon 2
\( n_{1} \) : taille de l’échantillon 1
\( n_{2} \) : taille de l’échantillon 2
Test Z à une proportion (test Z à une proportion)
Teste la proportion d’un échantillon unique par rapport à la proportion connue de l’hypothèse nulle. La distribution normale est utilisée pour le test Z à une proportion.
\(Z =\displaystyle \frac{\displaystyle \frac{x}{n} – p_{0} }{ \sqrt{\displaystyle \frac{ p_{0}(1-p_{0}) }{n} }}\)
\(p_{0}\) : proportion d’échantillon attendue
\(n\) : taille de l’échantillon
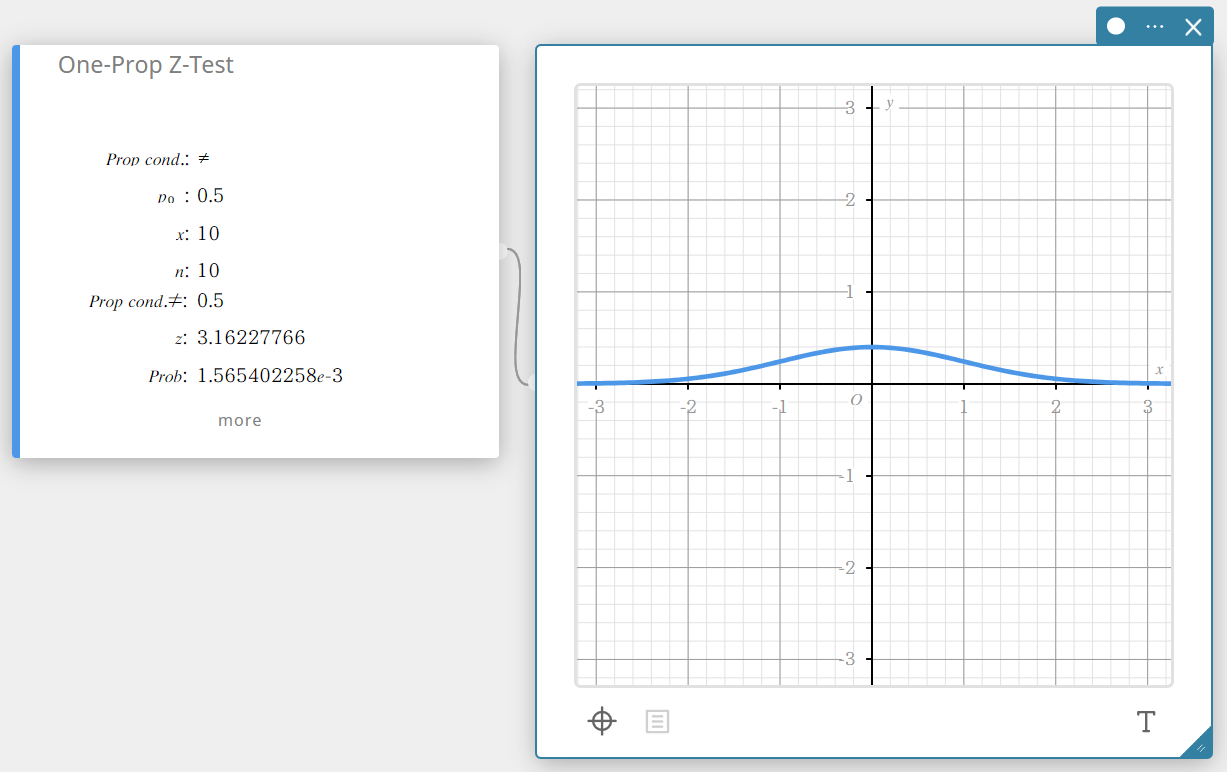
- Termes d’entrée
Prop cond : condition de test de proportion d’échantillon (“\(\neq\)” spécifie un test bilatéral, “<” spécifie un test unilatéral inférieur, “>” spécifie un test unilatéral supérieur.)
\(p_{0}\) : proportion d’échantillon attendue(\( 0 < p_{0} < 1 \))
\(x\) : valeur d’échantillon (entier, \( x \geq 0 \))
\(n\) : taille de l’échantillon (entier positif) -
Conditions de sortie
Prop Cond \(\neq\) : condition de test de proportion d’échantillon
\(z\) : z valeur
Prob : \(p\) valeur
\(\hat{p}\) : proportion estimée de l’échantillon
Test Z à deux proportions (test Z à deux proportions)
Teste la différence entre deux proportions d’échantillon. La distribution normale est utilisée pour le test Z à deux proportions.
\( Z =\displaystyle \frac{\displaystyle \frac{x_{1}}{n_{1}} -\displaystyle \frac{x_{2}}{n_{2}} }{ \sqrt{ \hat{p} \left(1-\hat{p} \right) \left(\displaystyle \frac{1}{n_{1}} +\displaystyle \frac{1}{n_{2}} \right) } }\)
\(x_{1}\) : valeur des données de l’échantillon 1
\(x_{2}\) : valeur des données de l’échantillon 2
\(n_{1}\) : taille de l’échantillon 1
\(n_{2}\) : taille de l’échantillon 2
\(\hat{p}\) : proportion estimée de l’échantillon
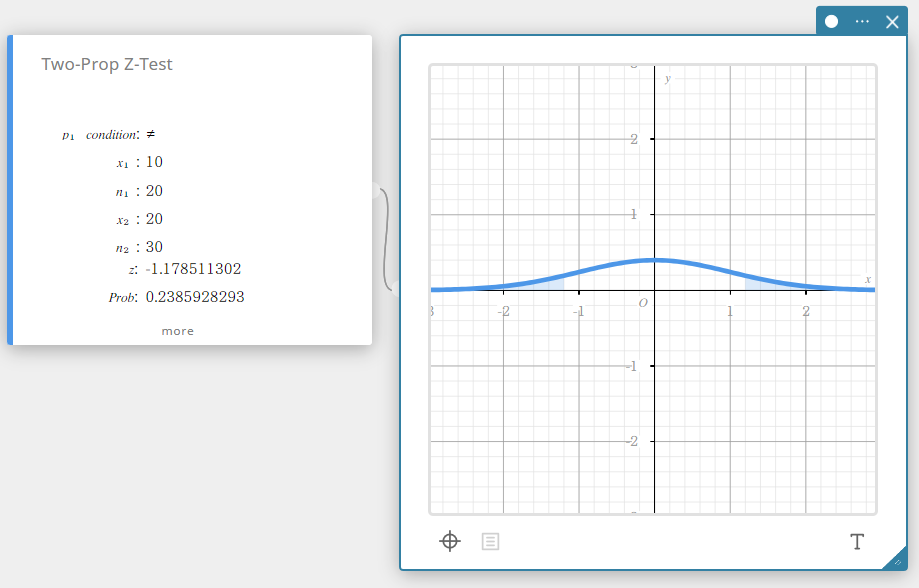
- Termes d’entrée
\(p_{1}\) conditions de test de proportion d’échantillon (“\(\neq\)” spécifie un test bilatéral, “<” spécifie un test unilatéral où l’échantillon 1 est plus petit que l’échantillon 2, “>” spécifie un test unilatéral où l’échantillon 1 est supérieur à l’échantillon 2.)
\(x_{1}\) : valeur des données de l’échantillon 1(entier, \(x_{1}\) doit être inférieur ou égal à \(n_{1}\))
\(n_{1}\) : taille de l’échantillon 1 (entier positif)
\(x_{2}\) : valeur des données de l’échantillon 2 (ientier, \(x_{2}\) doit être inférieur ou égal à \(n_{2}\))
\(n_{2}\) : taille de l’échantillon 2 (entier positif) -
Conditions de sortie
\(z\) : z valeur
Prob : \(p\) valeur
\(\hat{p}_{1}\) : proportion estimée de l’échantillon 1
\(\hat{p}_{2}\) : proportion estimée de l’échantillon 2
\(\hat{p}\) : proportion estimée de l’échantillon
Test \(t\) sur un échantillon
Teste la moyenne d’un échantillon unique par rapport à la moyenne connue de l’hypothèse nulle lorsque l’écart type de la population est inconnu. La distribution t est utilisée pour le Test \(t\) sur un échantillon.
\(t =\displaystyle \frac{ \overline{x} – \mu_{0} }{\displaystyle \frac{ s_{x} }{ \sqrt{n} } }\)
\(\overline{x}\) : moyenne de l’échantillon
\(\mu_{0}\) : moyenne de population supposée
\(s_{x}\) : écart type de l’échantillon
\(n\) : taille de l’échantillon
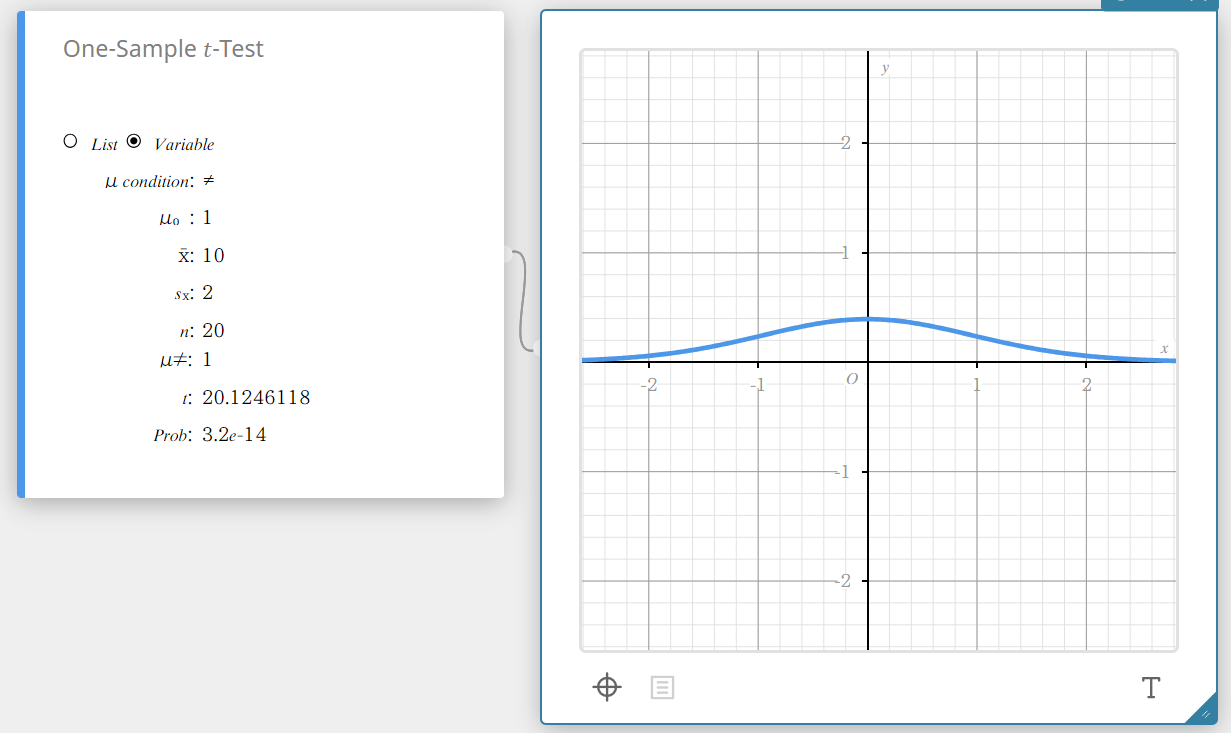
Type de données : Variable
- Termes d’entrée
Condition \(\mu\) : Conditions de test de la valeur moyenne de la population (“\(\neq\)” spécifie un test bilatéral, “<” spécifie un test unilatéral inférieur, “>” spécifie un test unilatéral supérieur.)
\(\mu_{0}\) : moyenne de population supposée
\(\overline{x}\) : moyenne de l’échantillon
\(s_{x}\) : écart type de l’échantillon(\( s_{x} > 0 \))
\(n\) : taille de l’échantillon (positive integer) -
Conditions de sortie
\(\mu \ne\) : conditions de test de la valeur moyenne de la population
\(t) : valeur (t)
Prob : valuer (p)
Type de données : Liste
- Termes d’entrée
\(\mu\) condition : conditions de test de la valeur moyenne de la population (“\(\neq\)” spécifie un test bilatéral, “<” spécifie un test unilatéral inférieur, “>” spécifie un test unilatéral supérieur.)
\(\mu_{0}\) : moyenne de population supposée
Liste : liste de données
Freq : fréquence (1 ou nom de la liste) -
Conditions de sortie
\(\mu \ne\) : conditions de test de la valeur moyenne de la population
\(t) : valeur (t)
Prob : valeur (p)
\(\overline{x}\) : moyenne de l’échantillon
\(s_{x}\) : écart type de l’échantillon
\(n\) : taille de l’échantillon
Test \(t\) à deux échantillons
Teste la différence entre deux moyennes lorsque les écarts types des deux populations sont inconnus. La distribution t est utilisée pour le Test \(t\) à deux échantillons.
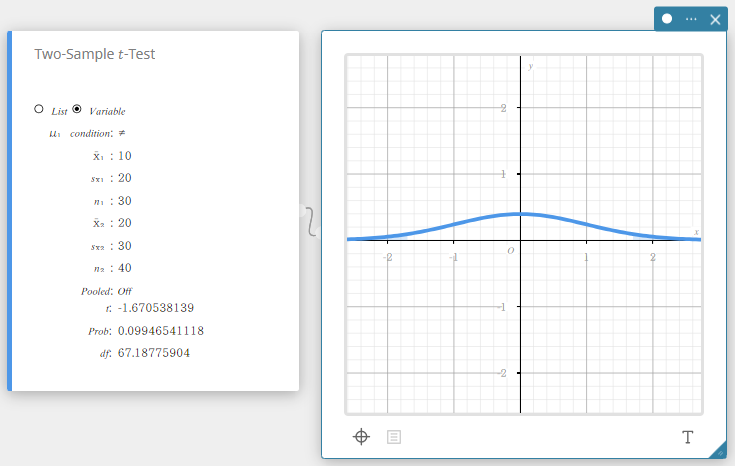
- Lorsque les deux écarts types de population sont égaux (regroupés)
\(t=\displaystyle \frac{\overline{x}_1-\overline{x}_2}{\sqrt{{s_{p}}^2 \left(\displaystyle \frac{1}{n_1} + \displaystyle \frac{1}{n_2} \right)}}\)
\(df=n_1+n_2-2\)
\(s_p=\sqrt{ \displaystyle \frac{(n_1-1){s_{x_1}}^2 + (n_2-1){s_{x_2}}^2}{n_1+n_2-2} }\) -
Lorsque les deux écarts types de population ne sont pas égaux (non regroupés)
\(t=\displaystyle \frac{\overline{x}_1-\overline{x}_2}{\sqrt{\displaystyle \frac{{s_{x_1}}^2}{n_1} + \displaystyle \frac{{s_{x_2}}^2}{n_2}}}\)
\(df =\displaystyle \frac{1}{\displaystyle \frac{C^2}{n_1-1} + \displaystyle \frac{(1-C)^2}{n_2-1}}\)
\(C =\displaystyle \frac{\displaystyle \frac{{s_{x_1}}^2}{n_1}}{\displaystyle \frac{{s_{x_1}}^2}{n_1} +\displaystyle \frac{{s_{x_2}}^2}{n_2}}\)
\(x_1\): moyenne de l’échantillon des données de l’échantillon 1
\(x_2\): moyenne de l’échantillon des données de l’échantillon 2
\(s_{x_1}\) : écart type de l’échantillon 1
\(s_{x_2}\) : écart type de l’échantillon 2
\(s_p\) : écart type de l’échantillon regroupé
\(n_1\) : taille de l’échantillon 1
\(n_2\) : taille de l’échantillon 2
Type de données : Variable
- Termes d’entrée
Condition \(\mu_1\) : conditions de test de la valeur moyenne de la population (“\(\neq\)” spécifie un test bilatéral, “<” spécifie un test unilatéral où l’échantillon 1 est plus petit que l’échantillon 2, “>” spécifie un test unilatéral où l’échantillon 1 est supérieur à l’échantillon 2.)
\(\overline{x}_1\) : moyenne de l’échantillon des données de l’échantillon 1
\(s_{x_1}\) : moyenne de l’échantillon des données de l’échantillon 1(\(s_{x_1} > 0\))
\(n_1\) : taille de l’échantillon 1 (entier positif)
\(\overline{x}_2\) : moyenne de l’échantillon des données de l’échantillon 2
\(s_{x_2}\) : écart type de l’échantillon 2(\(s_{x_2} > 0\))
\(n_2\) : taille de l’échantillon 2 (entier positif) -
Conditions de sortie
\(t\) : valeur \(t\)
Prob : valeur \(p\)
\(df\) : degrés de liberté
\(s_p\) : écart type de l’échantillon regroupé
Type de données : Liste
- Termes d’entrée
Condition \(\mu_1\) : conditions de test de la valeur moyenne de la population (“\(\neq\)” spécifie un test bilatéral, “<” spécifie un test unilatéral où l’échantillon 1 est plus petit que l’échantillon 2, “>” spécifie un test unilatéral où l’échantillon 1 est supérieur à l’échantillon 2.)
List(1) : liste où se trouvent les données de l’échantillon 1
List(2) : liste où se trouvent les données de l’échantillon 2
Freq(1) : fréquence de l’échantillon 1 (1 ou nom de la liste)
Freq(2) : fréquence de l’échantillon 2 (1 ou nom de la liste)
Pooled : Activé (variances égales) ou Désactivé (variances inégales) -
Conditions de sortie
\(t\) : valeur \(t\)
Prob : valeur \(p\)
\(df\) : degrés de liberté
\( \overline{x}_{1} \) : moyenne de l’échantillon des données de l’échantillon 1
\( \overline{x}_{2} \) : moyenne de l’échantillon des données de l’échantillon 2
\( s_{x_{1}} \) : écart type de l’échantillon 1
\( s_{x_{2}} \) : écart type de l’échantillon 2
\(s_p\) : écart type de l’échantillon regroupé
\( n_{1} \) : taille de l’échantillon 1
\( n_{2} \) : taille de l’échantillon 2
Test \(t\) de régression linéaire (Régression linéaire \(t\) -Test)
Teste la relation linéaire entre les variables appariées ( x , y ). La méthode des moindres carrés est utilisée pour déterminer a et b , qui sont les coefficients de la formule de régression \(y = a + b \cdot x\). La valeur p est la probabilité de la pente de régression de l’échantillon ( b ) à condition que l’hypothèse nulle soit vraie, \(\beta = 0\). La distribution t est utilisée pour le Test \(t\) de régression linéaire.
\(t=r\sqrt{\displaystyle \frac{n-2}{1-r^2}}\)
\( \displaystyle b=\left\{ \sum_{i=1}^n (x_i-\overline{x})(y_i-\overline{y}) \right\} / \left\{\sum_{i=1}^n (x_i-\overline{x})^2 \right\}\)
\(a=\overline{y}-b\overline{x}\)
\(a\) : terme constant de régression (ordonnée à l’origine)
\(b\) : coefficient de régression (pente)
\(n\) : taille de l’échantillon(\(n \ge 3\))
\(r\) : coefficient de corrélation
\(r^2\) : coefficient de détermination
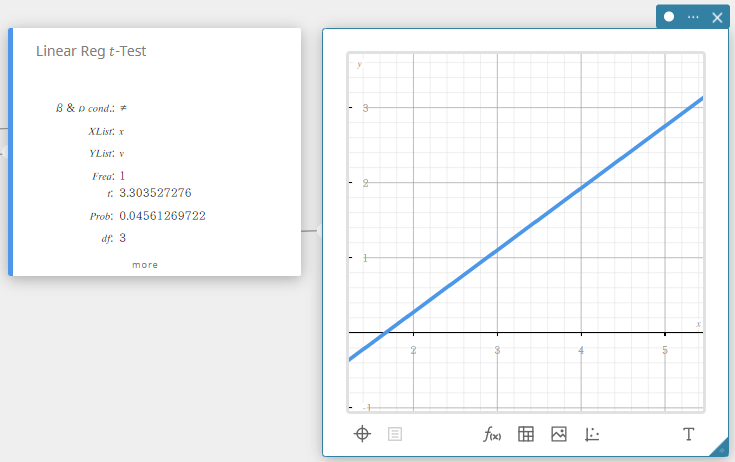
- Termes d’entrée
\(\beta\ \&\ \rho\) cond : conditions de test (“\(\neq\)” spécifie un test bilatéral, “<” spécifie un test unilatéral inférieur, “>” spécifie un test unilatéral supérieur.)
XList : liste de données x
YList : liste de données y
Freq : fréquence (1 ou nom de la liste) -
Conditions de sortie
\(t\) : valeur \(t\)
Prob : valeur \(p\)
\(df\) : degrés de liberté
\(a\) : terme constant de régression (ordonnée à l’origine)
\(b\) : coefficient de régression (pente)
se : erreur type d’estimation sur la droite de régression des moindres carrés
\(r\) : coefficient de corrélation
\(r^2\) : coefficient de détermination
SEb: erreur standard de la pente des moindres carrés
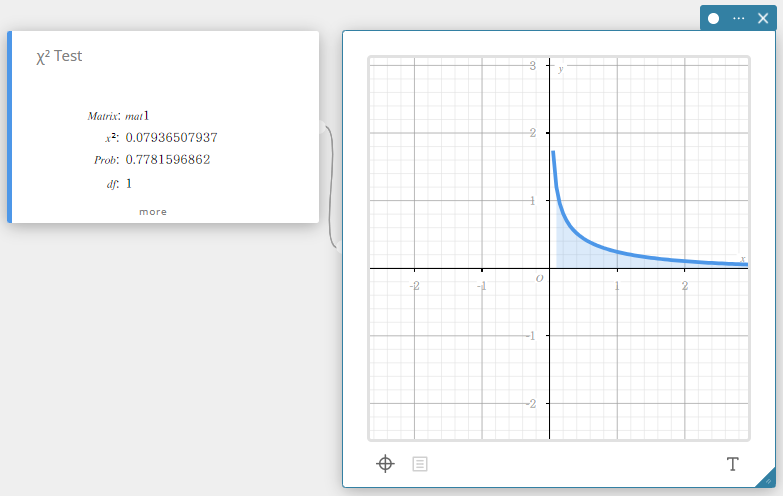
Test \(\chi^2\)
Teste l’indépendance de deux variables catégorielles disposées sous forme matricielle. Le test d’indépendance \(\chi^2\) compare la matrice observée à la matrice théorique attendue. La distribution \(\chi^2\) est utilisée pour le test \(\chi^2\).
NOTE
La taille minimale de la matrice est de 1×2. Une erreur se produit si la matrice ne comporte qu’une seule colonne.
Le résultat du calcul de la fréquence attendue est stocké dans la variable système nommée “Attendu”.
\( \chi^2 = \sum_{i=1}^{k}\sum_{j=1}^{l} \displaystyle \frac{(x_{ij}-F_{ij})^2}{F_{ij}} \)
\( F_{ij}=\frac{{\displaystyle\sum_{i=1}^k}x_{ij}\times{\displaystyle\sum_{j=1}^lx_{ij}}}{{\displaystyle\sum_{i=1}^k}{\displaystyle\sum_{j=1}^l}x_{ij}} \)
\( x_{ij}\) : L’élément à la ligne i, colonne j de la matrice observée
\( F_{ij}\) : L’élément à la ligne i, colonne j de la matrice attendue
- Termes d’entrée
Matrice : nom de la matrice contenant les valeurs observées (entiers positifs dans toutes les cellules pour les matrices 2×2 et plus ; nombres réels positifs pour les matrices à une ligne) -
Conditions de sortie
\(\chi^2\) : valeur \(\chi^2\)
Prob : valeur \(p\)
\(df\) : degrés de liberté
Observé : la matrice d’entrée des valeurs observées
Attendu : la matrice calculée des valeurs attendues
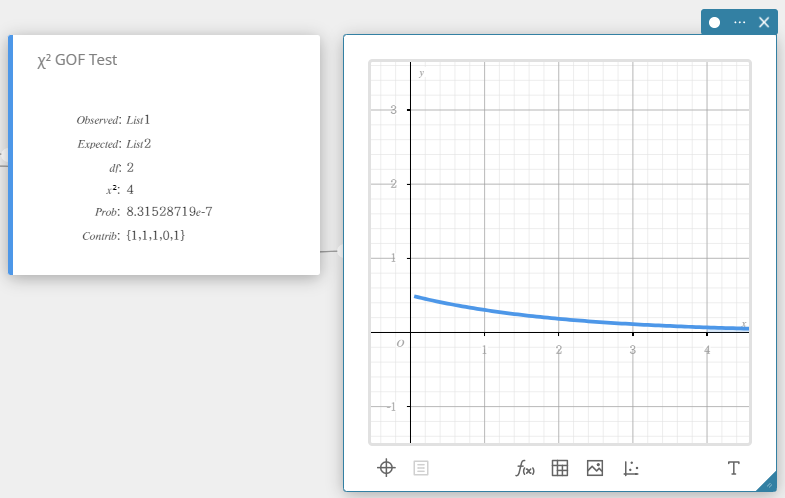
Test \(\chi^2\) GOF (Test d’adéquation \(\chi^2\))
Teste si le nombre observé d’échantillons de données correspond à une certaine distribution. Par exemple, il peut être utilisé pour déterminer la conformité à la distribution normale ou à la distribution binomiale.
\(\chi^2=\sum_i^k \displaystyle \frac{ (O_i – E_i )^2 }{E_i}\)
\(Contrib = \left\{\displaystyle \frac{ (O_1 – E_1 )^2 }{E_1} \ \displaystyle \frac{ (O_2 – E_2 )^2 }{E_2} \cdots \displaystyle \frac{ (O_k – E_k )^2 }{E_k} \right\} \)
\(O_i\) : Le i-ème élément de la liste observée
\(E_i\) : Le i-ème élément de la liste attendue
- Termes d’entrée
Liste observée : nom de la liste contenant les décomptes observés (toutes les cellules sont des entiers positifs)
Liste attendue : nom de la liste permettant de sauvegarder la fréquence attendue
\(df\) : degrés de liberté -
Conditions de sortie
\(\chi^2\) : valeur \(\chi^2\)
Prob : valeur \(p\)
\(df\) : degrés de liberté
Contrib : nom de la liste précisant la contribution de chaque comptage observé
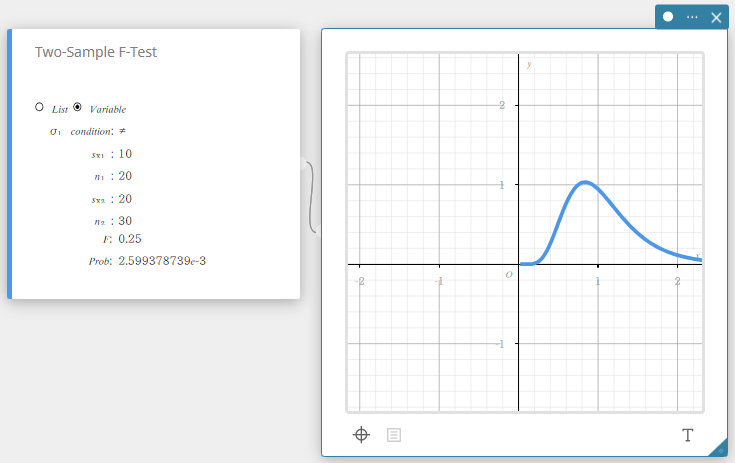
Test F à deux échantillons
Teste le rapport entre les variances de deux échantillons aléatoires indépendants. La distribution F est utilisée pour le test F à deux échantillons.
\( F=\displaystyle \frac{{S_{x_1}}^2}{{S_{x_2}}^2}\)
Type de données: Variable
- Termes d’entrée
Condition \( \sigma_1\): conditions de test de l’écart type de la population (“\( \neq\)” spécifie un test bilatéral, “<” spécifie un test unilatéral où l’échantillon 1 est plus petit que l’échantillon 2, “>” spécifie un test unilatéral où l’échantillon 1 est supérieur à l’échantillon 2.)
\( s_{x_1}\) : écart type de l’échantillon 1( \( s_{x_1} > 0\))
\( n_1\) : taille de l’échantillon 1 (entier positif)
\( s_{x_2}\) : écart type de l’échantillon 2( \( s_{x_2} > 0\))
\( n_2\) : taille de l’échantillon 2 (entier positif) -
Conditions de sortie
\( F\) : valeur F
Prob : valeur p
Type de données : Liste
- Termes d’entrée
Condition \( \sigma_1\): conditions de test de l’écart type de la population (“\( \neq\)” spécifie un test bilatéral, “<”spécifie un test unilatéral où l’échantillon 1 est plus petit que l’échantillon 2, “>” spécifie un test unilatéral où l’échantillon 1 est supérieur à l’échantillon 2.)
List(1) : liste où se trouvent les données de l’échantillon 1
List(2) : liste où se trouvent les données de l’échantillon 2
Freq(1) : fréquence de l’échantillon 1 (1 ou nom de la liste)
Freq(2) : fréquence de l’échantillon 2 (1 ou nom de la liste) -
Conditions de sortie
\( F\) : valeur F
Prob : valeur p
\( \overline{x}_{1} \) : moyenne de l’échantillon des données de l’échantillon 1
\( \overline{x}_{2} \) : moyenne de l’échantillon des données de l’échantillon 2
\( s_{x_{1}} \) : écart type de l’échantillon 1
\( s_{x_{2}} \) : écart type de l’échantillon 2
\( n_{1} \) : taille de l’échantillon 1
\( n_{2} \) : taille de l’échantillon 2
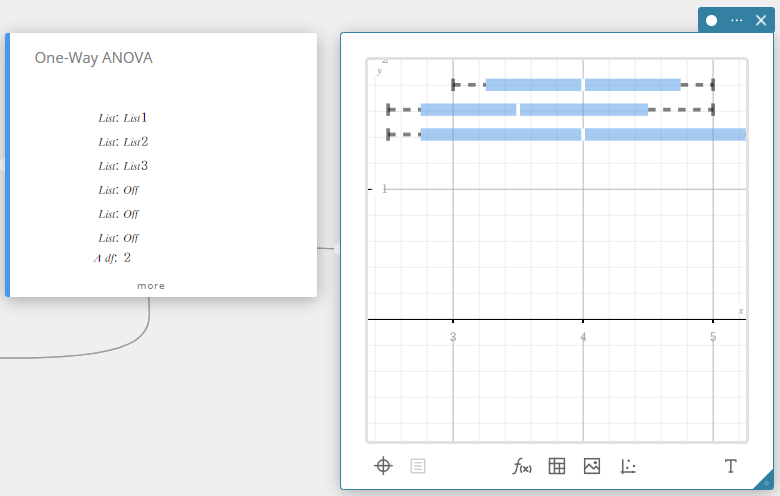
One-Way ANOVA (Analyse de variance unidirectionnelle)
Teste l’hypothèse selon laquelle les moyennes de plusieurs populations sont égales. Il compare la moyenne d’un ou plusieurs groupes en fonction d’une variable ou d’un facteur indépendant.
- Termes d’entrée
FactorList(A) : liste où se situent les niveaux du Facteur A
DependentList : liste où se trouvent les exemples de données - Conditions de sortie
A df : degrés de liberté du facteur A
A MS : carré moyen du facteur A
A SS : somme des carrés du facteur A
A F : F valeur F du facteur A
A p : pvaleur p du facteur A
Err df : degrés de liberté d’erreur
Err MS : carré moyen de l’erreur
Err SS : somme des carrés d’erreur
Two-Way ANOVA (Analyse de variance bidirectionnelle)
Teste l’hypothèse selon laquelle les moyennes de plusieurs populations sont égales. Il examine l’effet de chaque variable indépendamment ainsi que leur interaction les unes avec les autres en fonction d’une variable dépendante.
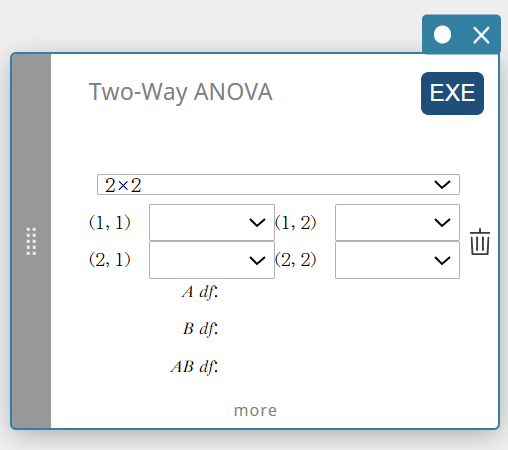
- Termes d’entrée
2×2: type de table de données
FactorList(A) : liste où se situent les niveaux du Facteur A
FactorList(B) : liste où se situent les niveaux du Facteur B
DependentList : liste où se trouvent les exemples de données -
Conditions de sortie
A df : degrés de liberté du facteur A
A MS : carré moyen du facteur A
A SS : somme des carrés du facteur A
A F : F valeur F du facteur A
A p : p valeur p du facteur A
B df : degrés de liberté du facteur B
B MS : carré moyen du facteur B
B SS : somme des carrés du facteur B
B F : F valeur F du facteur B
B p : p valeur p du facteur B
AB df : degrés de liberté du facteur A × facteur B
AB MS : carré moyen du facteur A × facteur B
AB SS : somme des carrés du facteur A × facteur B
AB F : F valeur F du facteur A × facteur B
AB p : p valeur p du facteur A × facteur B
Err df : degrés de liberté d’erreur
Err MS : carré moyen de l’erreur
Err SS : somme des carrés d’erreur
Intervalles de confiance
Intervalle Z pour un échantillon
Calcule l’intervalle de confiance pour la moyenne de la population en fonction d’une moyenne d’échantillon et d’un écart type de population connu.
\(Lower = \overline{x}-Z \left(\displaystyle \frac{\alpha}{2} \right) \displaystyle \frac{\sigma}{\sqrt{n}}\)
\(Upper = \overline{x}+Z \left(\displaystyle \frac{\alpha}{2} \right) \displaystyle \frac{\sigma}{\sqrt{n}}\)
\(\alpha\) est le niveau de signification et \(100(1 – \alpha)\%\) est le niveau de confiance. Lorsque le niveau de confiance est de \(95\%\), par exemple, vous saisirez 0.95, ce qui produit α = 1 – 0.95 = 0.05.
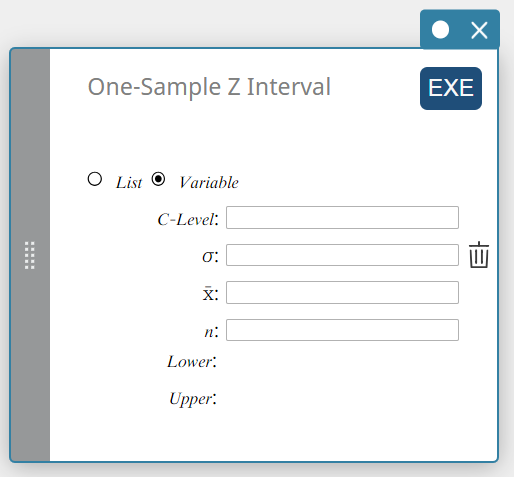
Type de données : Variable
- Termes d’entrée
Niveau C : niveau de confiance(\(0 \le\) C-Level \(\lt 1\))
\( \sigma \) : écart type de la population(\( \sigma > 0 \))
\( \overline{x} \) : moyenne de l’échantillon
\( n \) : taille de l’échantillon (entier positif) -
Conditions de sortie
Inférieur : limite inférieure de l’intervalle (bord gauche)
Supérieur : limite supérieure de l’intervalle (bord droit)
Type de données : Liste -
Termes d’entrée
Niveau C : niveau de confiance(\(0 \le\) Niveau C \(\lt 1\))
\( \sigma \) : écart type de la population(\( \sigma > 0 \))
Liste : liste où se trouvent les exemples de données
Freq : fréquence de l’échantillon (1 ou nom de la liste) -
Conditions de sortie
Inférieur : limite inférieure de l’intervalle (bord gauche)
Supérieur : limite supérieure de l’intervalle (bord droit)
\( \overline{x} \) : moyenne de l’échantillon
\( s_{x} \) : écart type de l’échantillon
\( n \) : taille de l’échantillon
Intervalle Z à deux échantillons
Calcule l’intervalle de confiance pour la différence entre les moyennes de la population en fonction de la différence entre les moyennes de l’échantillon lorsque les écarts types de la population sont connus.
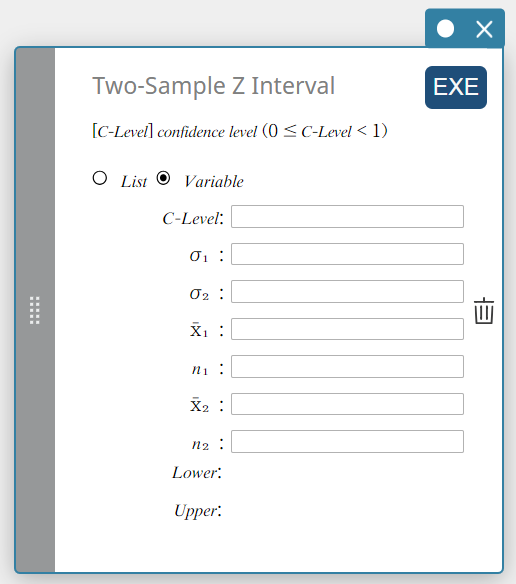
\(Lower = \left( \overline{x}_1-\overline{x}_2 \right) -Z \left(\displaystyle \frac{\alpha}{2} \right) \sqrt{\displaystyle \frac{{\sigma_1}^2}{n_1} + \displaystyle \frac{{\sigma_2}^2}{n_2} }\)
\(Upper = \left( \overline{x}_1-\overline{x}_2 \right) +Z \left(\displaystyle \frac{\alpha}{2} \right) \sqrt{\displaystyle \frac{{\sigma_1}^2}{n_1} + \displaystyle \frac{{\sigma_2}^2}{n_2} }\)
Type de données : Variable
- Termes d’entrée
Niveau C : niveau de confiance(\(0 \le\) Niveau Cl \(\lt 1\))
\( \sigma_{1} \) : écart type de la population de l’échantillon 1(\( \sigma_{1} > 0 \))
\( \sigma_{2} \) : écart type de la population de l’échantillon 2(\( \sigma_{2} > 0 \))
\( \overline{x}_{1} \) : moyenne de l’échantillon des données de l’échantillon 1
\( n_{1} \) : taille de l’échantillon 1 (entier positif)
\( \overline{x}_{2} \) : moyenne de l’échantillon des données de l’échantillon 2
\( n_{2} \) : taille de l’échantillon 2 (entier positif) -
Conditions de sortie
Inférieur : limite inférieure de l’intervalle (bord gauche)
Supérieur : limite supérieure de l’intervalle (bord droit)
Type de données : Liste -
Termes d’entrée
Niveau C : niveau de confiance(\(0 \le\) Niveau C \(\lt 1\))
\( \sigma_{1} \) : écart type de la population de l’échantillon 1(\( \sigma_{1} > 0 \))
\( \sigma_{2} \) : écart type de la population de l’échantillon 2(\( \sigma_{2} > 0 \))
List(1) : liste où se trouvent les données de l’échantillon 1
List(2) : liste où se trouvent les données de l’échantillon 2
Freq(1) : fréquence de l’échantillon 1 (1 ou nom de la liste)
Freq(2) : fréquence de l’échantillon 2 (1 ou nom de la liste) - Conditions de sortie
Inférieur : limite inférieure de l’intervalle (bord gauche)
Supérieur : limite supérieure de l’intervalle (bord droit)
\( \overline{x}_{1} \) : moyenne de l’échantillon des données de l’échantillon 1
\( \overline{x}_{2} \) : moyenne de l’échantillon des données de l’échantillon 2
\( s_{x_{1}} \) : écart type de l’échantillon 1
\( s_{x_{2}} \) : écart type de l’échantillon 2
\( n_{1} \) : taille de l’échantillon 1
\( n_{2} \) : taille de l’échantillon 2
Intervalle Z à une proportion (intervalle Z à une proportion)
Calcule l’intervalle de confiance pour la proportion de population sur la base d’une proportion d’échantillon unique.
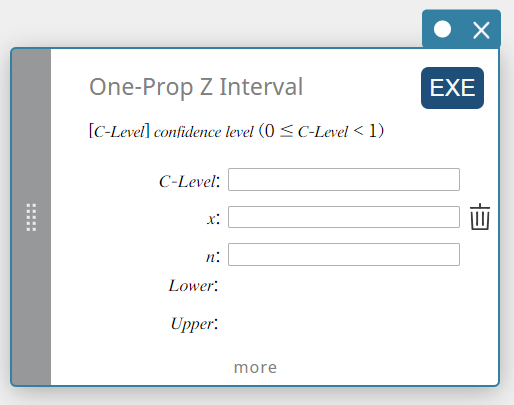
\(Lower =\displaystyle \frac{x}{n}-Z \left(\displaystyle \frac{\alpha}{2} \right) \sqrt{\displaystyle \frac{1}{n} \left(\displaystyle \frac{x}{n} \left( 1- \displaystyle \frac{x}{n} \right) \right) }\)
\(Upper =\displaystyle \frac{x}{n}+Z \left(\displaystyle \frac{\alpha}{2} \right) \sqrt{\displaystyle \frac{1}{n} \left(\displaystyle \frac{x}{n} \left( 1- \displaystyle \frac{x}{n} \right) \right) }\)
- Termes d’entrée
Niveau C : niveau de confiance(\(0 \le\) Niveau C \(\lt 1\))
\( x \) : données (0 ou entier positif)
\( n \) : taille de l’échantillon (entier positif) -
Conditions de sortie
Inférieur : limite inférieure de l’intervalle (bord gauche)
Supérieur : limite supérieure de l’intervalle (bord droit)
\(\hat{p}\) : proportion estimée de l’échantillon
Intervalle Z à deux proportions (intervalle Z à deux proportions)
Calcule l’intervalle de confiance pour la différence entre les proportions de population en fonction de la différence entre l’intervalle Z à deux proportions.
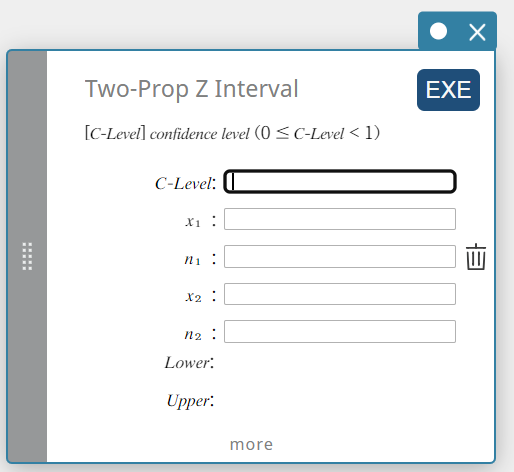
\( Lower =\displaystyle \frac{x_1}{n_1}- \displaystyle \frac{x_2}{n_2}-Z \left(\displaystyle \frac{\alpha}{2} \right) \sqrt{\displaystyle \frac{\displaystyle \frac{x_1}{n_1} \left( 1- \displaystyle\frac{x_1}{n_1} \right) }{n_1} + \displaystyle \frac{\displaystyle \frac{x_2}{n_2} \left( 1- \displaystyle \frac{x_2}{n_2} \right) }{n_2} } \)
\( Upper =\displaystyle \frac{x_1}{n_1}- \displaystyle \frac{x_2}{n_2}+Z \left(\displaystyle \frac{\alpha}{2} \right) \sqrt{ \displaystyle \frac{\displaystyle \frac{x_1}{n_1} \left( 1-\displaystyle \frac{x_1}{n_1} \right) }{n_1} +\displaystyle \frac{\displaystyle \frac{x_2}{n_2} \left( 1-\displaystyle\frac{x_2}{n_2} \right) }{n_2} } \)
- Termes d’entrée
Niveau C : niveau de confiance(\(0 \le\) Niveau C \(\lt 1\))
\(x_{1}\) : valeur des données de l’échantillon 1 (entier, \(x_{1}\) doit être inférieur ou égal à \(n_{1}\))
\(n_{1}\) : taille de l’échantillon 1 (entier positif)
\(x_{2}\) : valeur des données de l’échantillon 2 (entier, \(x_{2}\) doit être inférieur ou égal à \(n_{2}\))
\(n_{2}\) : Inférieur : limite inférieure de l’intervalle (bord gauche) -
Conditions de sortie
Inférieur : limite inférieure de l’intervalle (bord gauche)
Supérieur : limite supérieure de l’intervalle (bord droit)
\(\hat{p}_{1}\) : proportion estimée de l’échantillon 1
\(\hat{p}_{2}\) : proportion estimée de l’échantillon 2
Intervalle \(t\) à un échantillon
Calcule l’intervalle de confiance pour la moyenne de la population en fonction d’une moyenne d’échantillon et d’un écart type d’échantillon lorsque l’écart type de la population n’est pas connu.
\(Lower = \overline{x}-t_{n-1} \left(\displaystyle \frac{\alpha}{2} \right) \displaystyle \frac{s_x}{\sqrt{n}}\)
\(Upper = \overline{x}+t_{n-1} \left(\displaystyle \frac{\alpha}{2} \right) \displaystyle \frac{s_x}{\sqrt{n}}\)
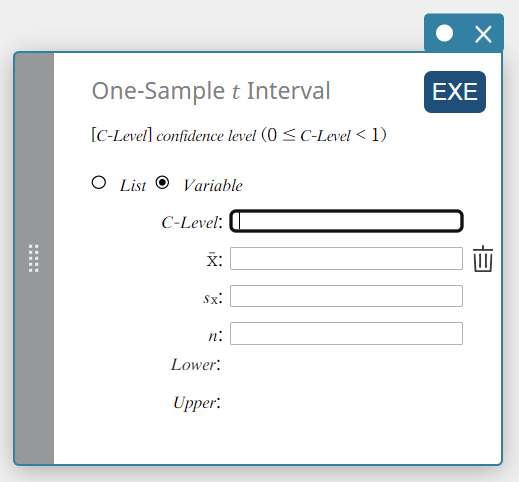
Type de données : Variable
- Termes d’entrée
Niveau C : niveau de confiance(\(0 \le\) Niveau C \(\lt 1\))
\( \overline{x} \) : moyenne de l’échantillon
\(s_{x}\) : écart type de l’échantillon(\( s_{x} \ge 0 \))
\(n\) : taille de l’échantillon (entier positif) -
Conditions de sortie
Inférieur : limite inférieure de l’intervalle (bord gauche)
Supérieur : limite supérieure de l’intervalle (bord droit)
Type de données : Liste
- Termes d’entrée
Niveau C : niveau de confiance(\(0 \le\) Niveau C \(\lt 1\))
Liste : liste où se trouvent les exemples de données
Freq : fréquence de l’échantillon (1 ou nom de la liste) -
Conditions de sortie
Inférieur : limite inférieure de l’intervalle (bord gauche)
Supérieur : limite supérieure de l’intervalle (bord droit)
\( \overline{x} \) : moyenne de l’échantillon
\( s_{x} \) : écart type de l’échantillon
\( n \) : taille de l’échantillon
Intervalle \(t\) à deux échantillonsl
Calcule l’Intervalle de confiance pour la différence entre les moyennes de la population en fonction de la différence entre les moyennes de l’échantillon et les écarts types de l’échantillon lorsque les écarts types de la population ne sont pas connus.
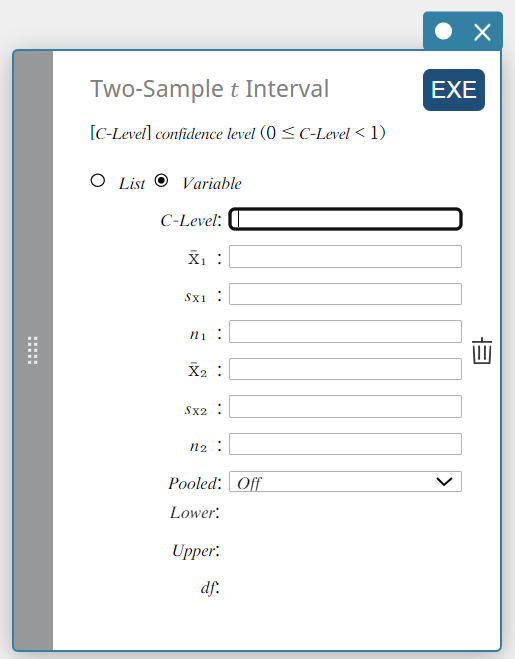
- Lorsque les deux écarts types de population sont égaux (regroupés)
\(Lower = \left( \overline{x}_1-\overline{x}_2 \right) -t_{n_1+n_2-2} \left(\displaystyle \frac{\alpha}{2} \right) \sqrt{{s_p}^2 \left(\displaystyle \frac{1}{n_1}+ \displaystyle \frac{1}{n_2} \right) }\)
\(Upper = \left( \overline{x}_1-\overline{x}_2 \right) +t_{n_1+n_2-2} \left(\displaystyle \frac{\alpha}{2} \right) \sqrt{{s_p}^2 \left(\displaystyle \frac{1}{n_1}+ \displaystyle \frac{1}{n_2} \right) }\)
- Lorsque les deux écarts types de population ne sont pas égaux (non regroupés)
\(Lower = \left( \overline{x}_1-\overline{x}_2 \right) -t_{df} \left(\displaystyle \frac{\alpha}{2} \right) \sqrt{ \left(\displaystyle \frac{{S_{x_1}}^2}{n_1}+ \displaystyle \frac{{S_{x_2}}^2}{n_2} \right) }\)
\(Upper = \left( \overline{x}_1-\overline{x}_2 \right) +t_{df} \left(\displaystyle \frac{\alpha}{2} \right) \sqrt{ \left(\displaystyle \frac{{S_{x_1}}^2}{n_1}+ \displaystyle \frac{{S_{x_2}}^2}{n_2} \right) }\)
\(df =\displaystyle \frac{1}{\displaystyle \frac{C^2}{n_1-1} + \displaystyle \frac{ \left( 1-C \right) ^2}{n_2-1}}\)
\(C=\displaystyle \frac{\displaystyle \frac{{S_{x_1}}^2}{n_1}}{ \left(\displaystyle \frac{{S_{x_1}}^2}{n_1} + \displaystyle \frac{{S_{x_2}}^2}{n_2} \right) }\)
Type de données : Variable
- Termes d’entrée
Niveau C : niveau de confiance(\(0 \le\) Niveau C \(\lt 1\))
\( \overline{x}_{1} \) : moyenne de l’échantillon des données de l’échantillon 1
\(s_{x_1}\) : écart type de l’échantillon 1(\(s_{x_1} \ge 0\))
\( n_{1} \) : taille de l’échantillon 1 (entier positif)
\( \overline{x}_{2} \) : moyenne de l’échantillon des données de l’échantillon 2
\(s_{x_2}\) : écart type de l’échantillon 2(\(s_{x_2} \ge 0\))
\( n_{2} \) : taille de l’échantillon 2 (entier positif) -
Conditions de sortie
Inférieur : limite inférieure de l’intervalle (bord gauche)
Supérieur : limite supérieure de l’intervalle (bord droit)
\(df\) : degrés de liberté
\(s_p\) : écart type de l’échantillon regroupé
Type de données : Liste
- Termes d’entrée
Niveau C : niveau de confiance(\(0 \le\) Niveau C \(\lt 1\))
List(1) : liste où se trouvent les données de l’échantillon 1
List(2) : liste où se trouvent les données de l’échantillon 2
Freq(1) : fréquence de l’échantillon 1 (1 ou nom de la liste)
Freq(2) : fréquence de l’échantillon 2 (1 ou nom de la liste)
Pooled : Activé (variances égales) ou Désactivé (variances inégales) -
Conditions de sortie
Inférieur : limite inférieure de l’intervalle (bord gauche)
Supérieur : limite supérieure de l’intervalle (bord droit)
\(df\) : degrés de liberté
\( \overline{x}_{1} \) : moyenne de l’échantillon des données de l’échantillon 1
\( \overline{x}_{2} \) : moyenne de l’échantillon des données de l’échantillon 2
\( s_{x_{1}} \) : écart type de l’échantillon 1
\( s_{x_{2}} \) : écart type de l’échantillon 2
\(s_p\) : écart type de l’échantillon regroupé
\( n_{1} \) : taille de l’échantillon 1
\( n_{2} \) : taille de l’échantillon 2
Probabilités
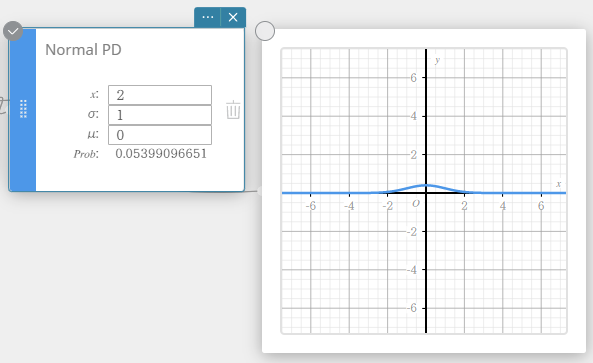
Densité de la loi Normale
Calcule la densité de probabilité normale pour une valeur spécifiée.
Spécifier σ = 1 et μ= 0 produit une distribution normale standard.
\(\displaystyle f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{\displaystyle -\frac{(x-\mu)^2}{2\sigma^2}} \qquad (\sigma>0)\)
- Termes d’entrée
\( x \) : valeur des données
\( \sigma \) : écart type de la population (\( \sigma > 0 \))
\( \mu \) : population signifie -
Conditions de sortie
Prob : densité de probabilité normale
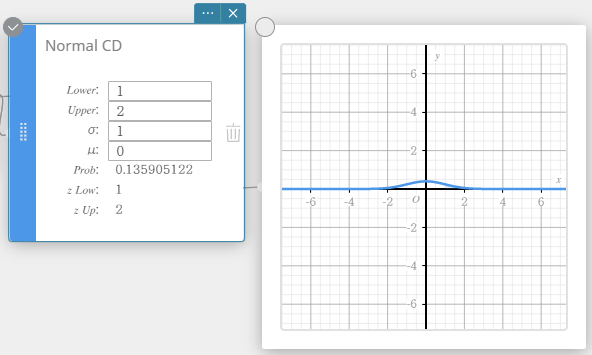
Fonction de répartition de la loi Normale
Calcule la probabilité cumulée d’une distribution normale entre une limite inférieure ( a ) et une limite supérieure ( b ).
\(\displaystyle p=\frac{1}{\sqrt{2\pi}\sigma}\int_a^b e^{ \scriptscriptstyle -\frac{(x-\mu)^2}{2\sigma^2} }dx\)
- Termes d’entrée
Inférieur : limite inférieure
Supérieur : limite supérieure
\( \sigma \) : écart type de la population (\( \sigma > 0 \))
\(\mu\) : population signifie -
Conditions de sortie
Prob : probabilité de distribution normale p
z Low : z valeur limite inférieure normalisée
z Up : z valeur limite supérieure normalisée
Densité de la loi \(t\) de Student
Calcule la densité de probabilité t de Student pour une valeur spécifiée.
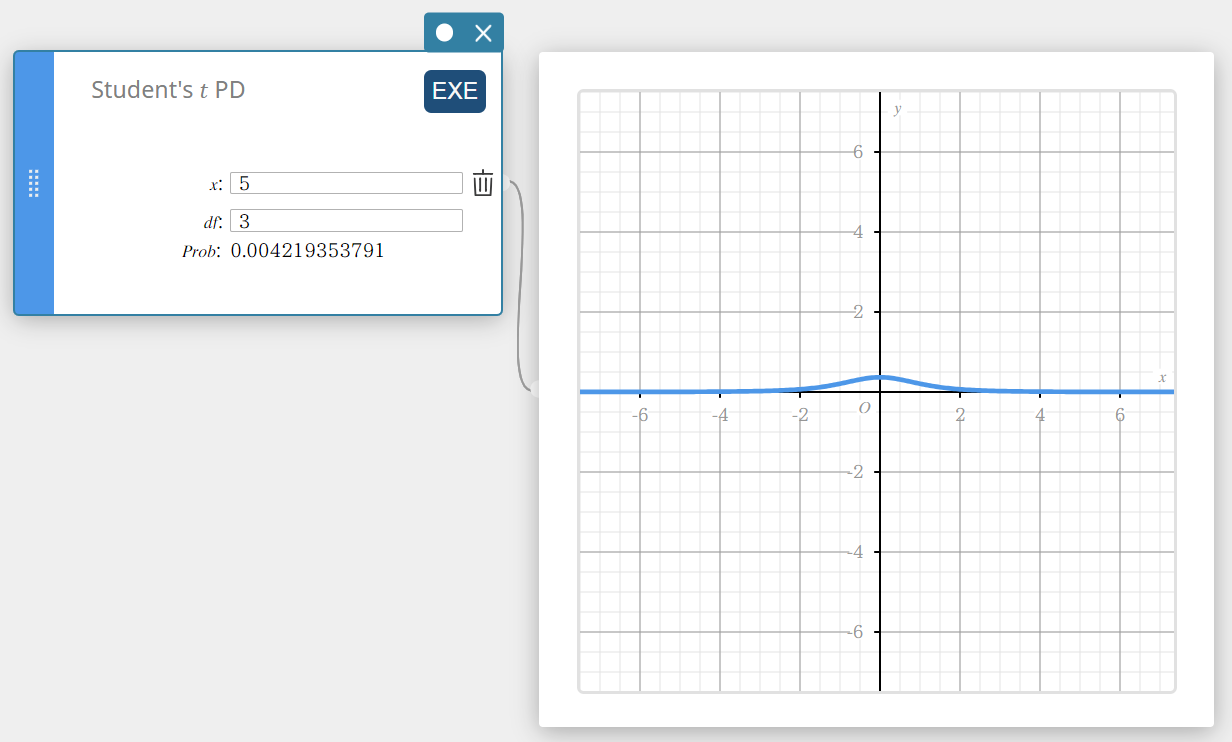
\(f(x)=\frac{\Gamma\left({\displaystyle\frac{df+1}2}\right)}{\Gamma\left({\displaystyle\frac{df}2}\right)}\times\frac{\left(1+{\displaystyle\frac{x^2}{df}}\right)^{-{\displaystyle\frac{df+1}2}}}{\sqrt{\pi\cdot df}}\)
- Termes d’entrée
\( x \) : valeur des données
\(df\) : degrés de liberté(\(df \gt 0\)) -
Conditions de sortie
Prob : Densité de probabilité t de Student
Fonction de répartition de la loi \(t\) de Student
Calcule la probabilité cumulée d’une distribution t de Student entre une limite inférieure ( a ) et une limite supérieure ( b ).
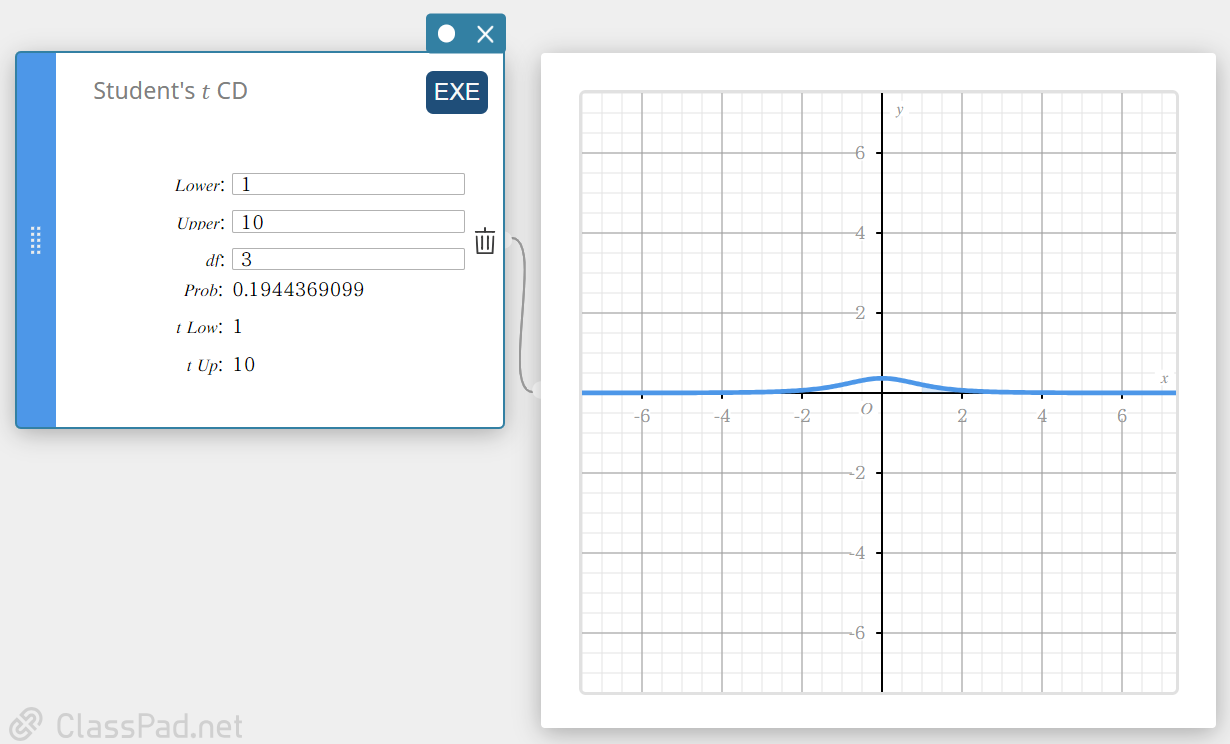
\( p=\displaystyle\frac{\Gamma \left(\displaystyle \frac{df+1}{2} \right) }{\Gamma \left(\displaystyle \frac{df}{2} \right) \sqrt{\pi \cdot df}}\int_a^b \left(\displaystyle 1+\frac{x^2}{df} \right) ^{-\displaystyle\frac{df+1}{2}}dx \)
- Termes d’entrée
Inférieur : limite inférieure
Supérieur : limite supérieure
\(df\) : degrés de liberté(\(df \gt 0\)) -
Conditions de sortie
Prob : Distribution t de Student
t Low : valeur limite inférieure que vous avez saisie
t Up : valeur limite supérieure que vous avez saisie
\(\chi^2\) PD (Densité de la loi du \(\chi^2\))
Calcule la densité de probabilité \(\chi^2\) pour une valeur spécifiée.
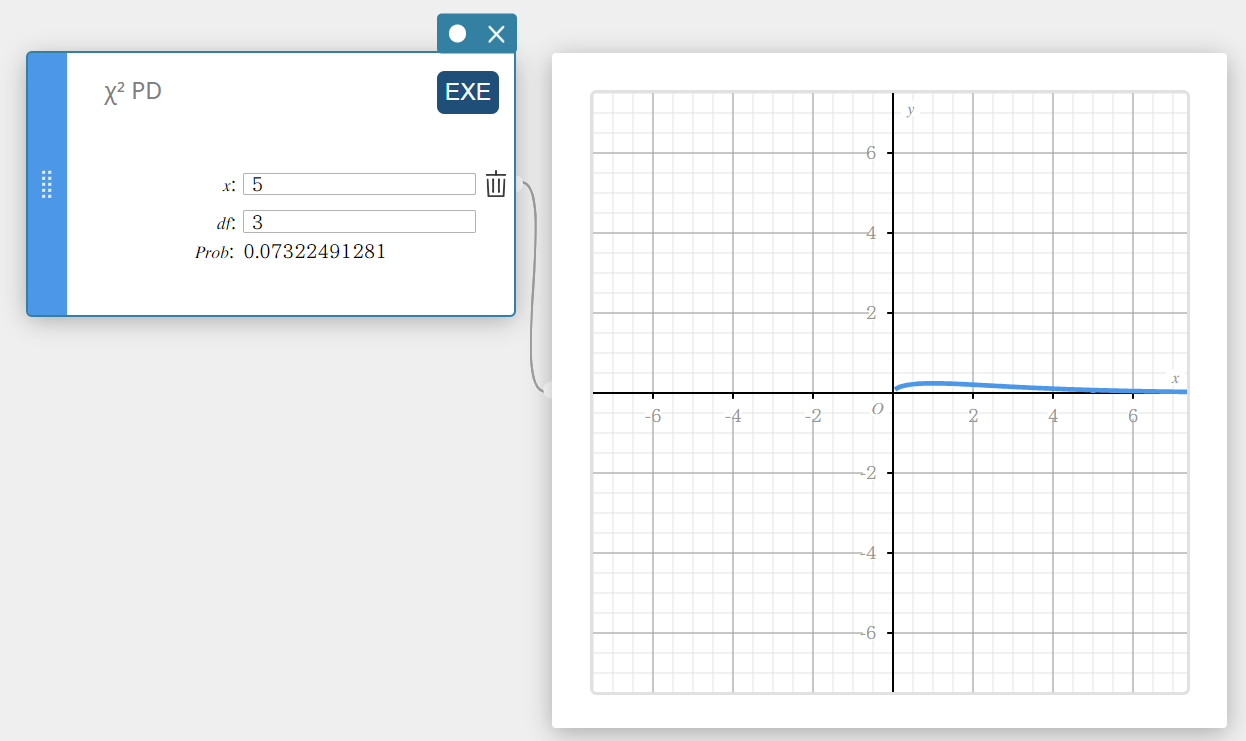
\(f \left( x \right) =\displaystyle\frac{1}{\Gamma \left(\displaystyle \frac{df}{2} \right) } \left(\displaystyle \frac{1}{2} \right) ^{\displaystyle\frac{df}{2}}x^{\displaystyle\frac{df}{2}-1}e^{-\displaystyle\frac{x}{2}}\)
- Termes d’entrée
\( x \) : valeur des données
\(df\) : degrés de liberté (entier positif) -
Conditions de sortie
Prob : densité de probabilité \(\chi^2\)
\(\chi^2\) CD (Fonction de répartition de la loi du \(\chi^2\))
Calcule la probabilité cumulée d’une distribution \(\chi^2\) entre une limite inférieure et une limite supérieure.
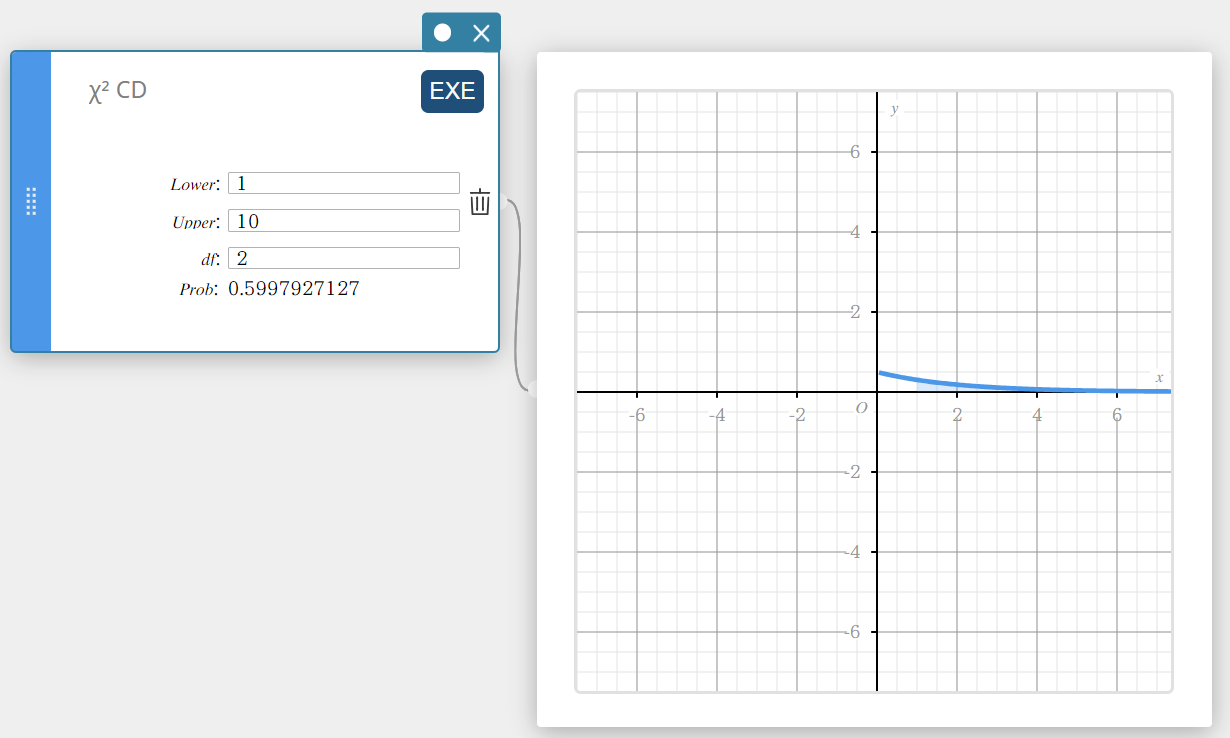
\(p=\cfrac{1}{\Gamma \left(\displaystyle \frac{df}{2} \right) } \left(\displaystyle \frac{1}{2} \right) ^{\displaystyle\frac{df}{2}}\int_a^b x^{\displaystyle\frac{df}{2}-1}e^{-\displaystyle\frac{x}{2}}dx\)
- Termes d’entrée
Inférieur : limite inférieure
Supérieur : limite supérieure
\(df\) : degrés de liberté (entier positif) -
Conditions de sortie
Prob : probabilité de distribution \(\chi^2\)
F PD (Densité de la loi F)
Calcule la densité de probabilité F pour une valeur spécifiée.
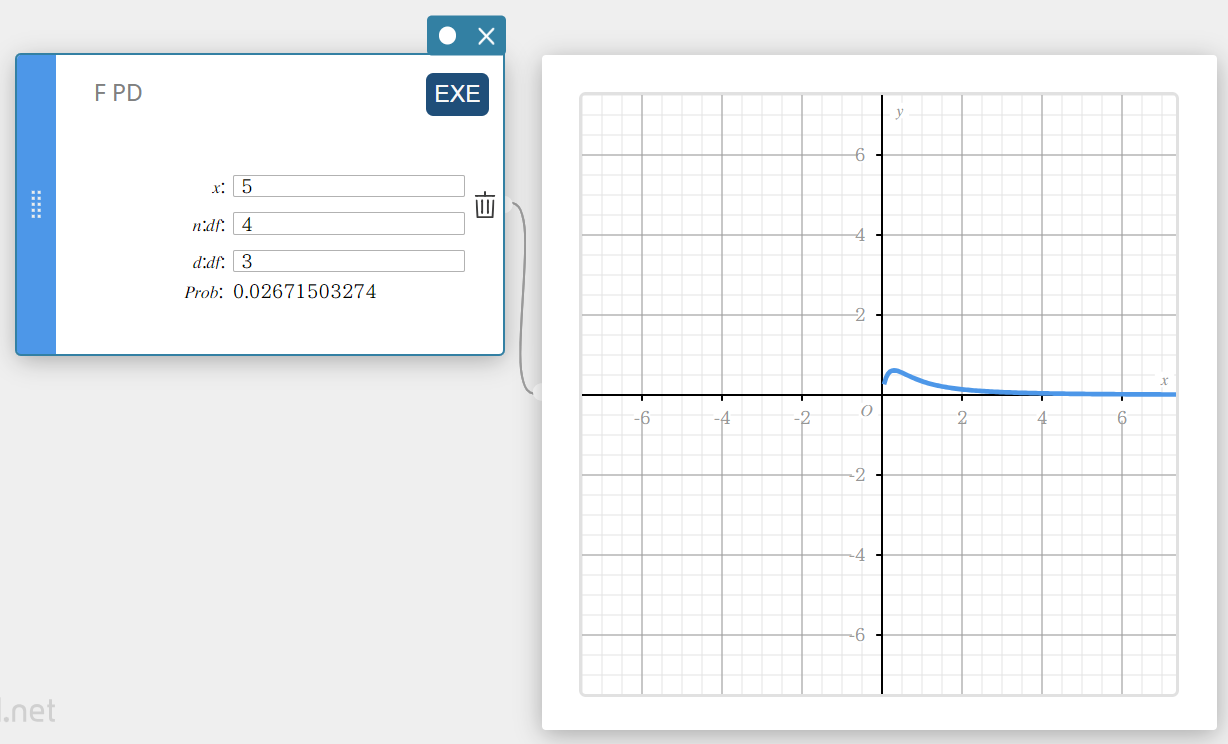
\(f(x)=\displaystyle\frac{\Gamma \left(\displaystyle \frac{n+d}{2} \right) }{\Gamma \left(\displaystyle \frac{n}{2} \right) \Gamma \left(\displaystyle \frac{d}{2} \right) } \left(\displaystyle \frac{n}{d} \right) ^{\displaystyle\frac{n}{2}}x^{\displaystyle\frac{n}{2}-1} \left( 1+ \displaystyle\frac{n \cdot x}{d} \right) ^{- \displaystyle\frac{n+d}{2}}\)
- Termes d’entrée
\( x \) : valeur des données
\( n:df \) : degrés de liberté du numérateur (entier positif)
\( d:df \) : degrés de liberté du dénominateur (entier positif) -
Conditions de sortie
Prob : F densité de probabilité
F CD (Fonction de répartition de la loi F)
Calcule la probabilité cumulée d’une distribution anF entre une limite inférieure et une limite supérieure.
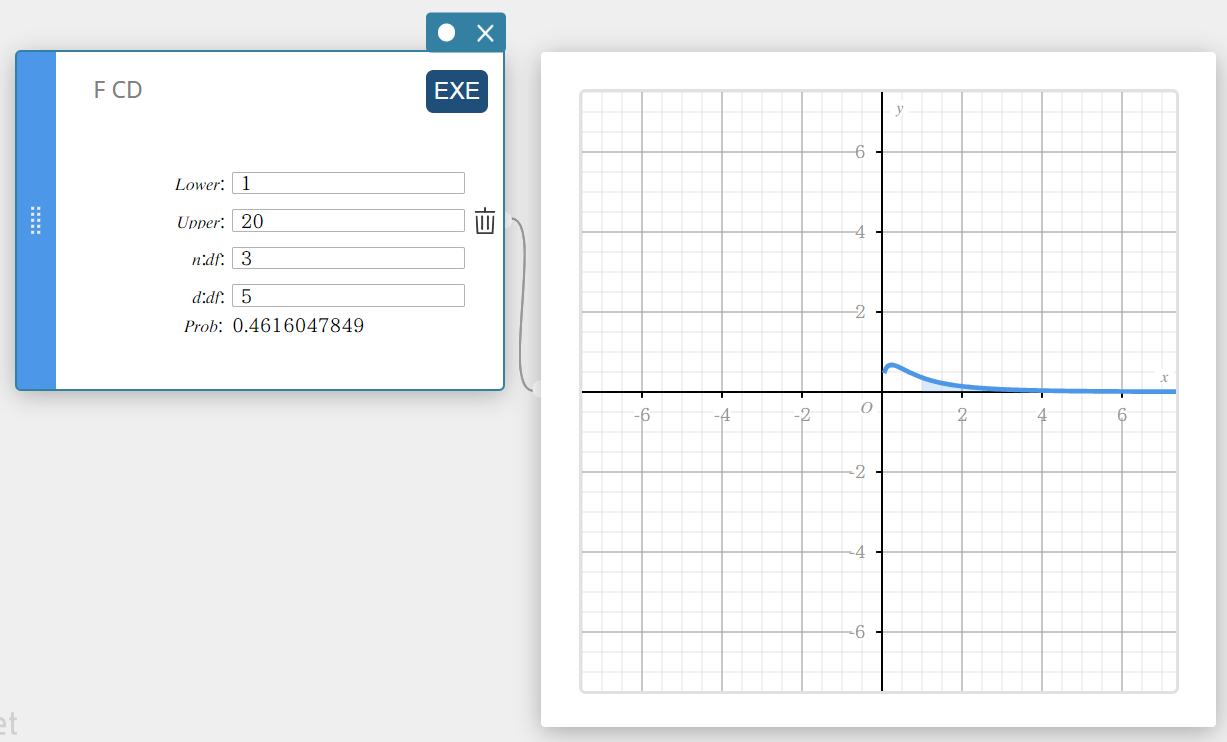
\(p=\displaystyle\frac{\Gamma \left(\displaystyle \frac{n+d}{2} \right) }{\Gamma \left(\displaystyle \frac{n}{2} \right) \Gamma \left(\displaystyle \frac{d}{2} \right) } \left(\displaystyle \frac{n}{d} \right) ^{\displaystyle\frac{n}{2}}\int_a^b x^{\displaystyle\frac{n}{2}-1} \left( 1+ \displaystyle\frac{n \cdot x}{d} \right) ^{- \displaystyle\frac{n+d}{2}}dx\)
- Termes d’entrée
Inférieur : limite inférieure
Supérieur : limite supérieure
\( n:df \) : degrés de liberté du numérateur (entier positif)
\( d:df \) : degrés de liberté du dénominateur (entier positif) -
Conditions de sortie
Prob : probabilité de distribution F
Binomial PD (Densité de la loi Binomiale)
Calcule la probabilité, dans une distribution binomiale, que le succès se produise lors d’un essai spécifié.
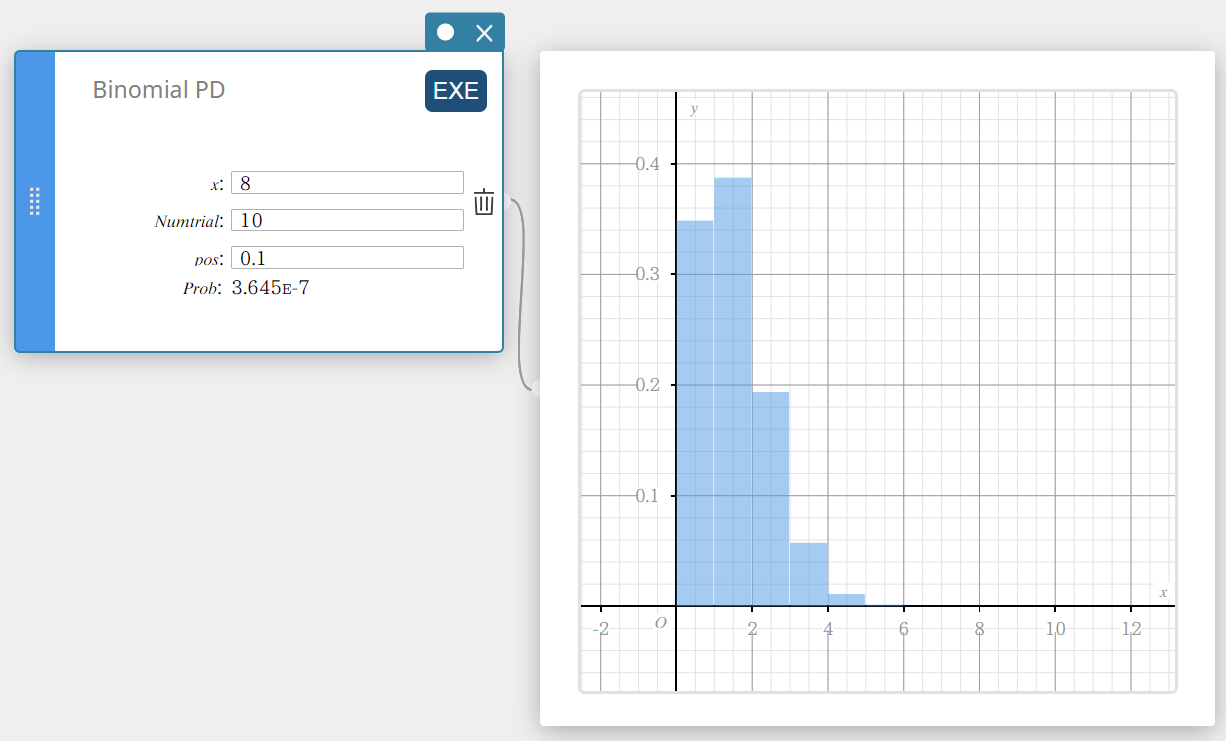
\(f(x)={}_nC_xp^x(1-p)^{n-x} \quad (x=0,1, \cdots,n)\)
\(p\) : probabilité de succès((0 \(≤\) p \(≤\) 1)
\(n\) : nombre d’essais
- Termes d’entrée
\( x \) : essai spécifié (entier de 0 à n)
Numtrial : nombre d’essais n (entier, n ≥ 0)
pos : probabilité de succès p (0 \(≤\) p \(≤\) 1) -
Conditions de sortie
Prob : probabilité binomiale
Binomial CD (Fonction de répartition de la loi Binomiale)
Calcule la probabilité cumulée dans une distribution binomiale que le succès se produise au moment ou avant un essai spécifié.
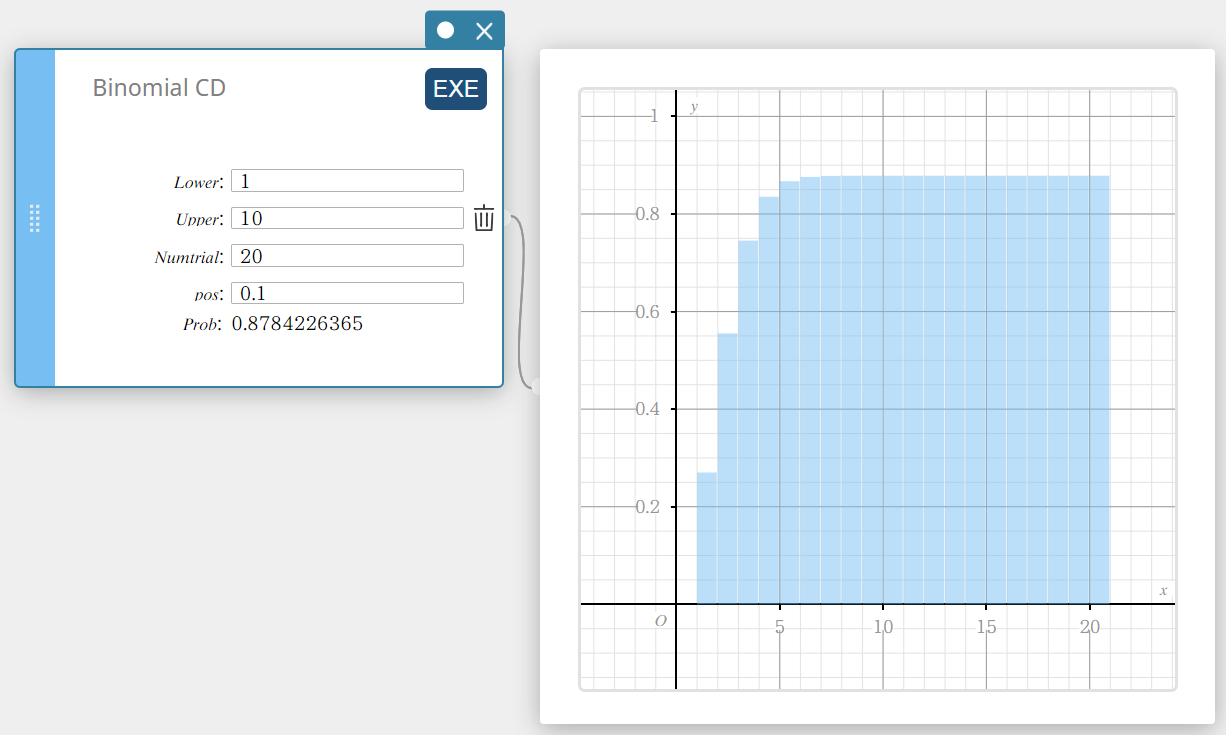
- Termes d’entrée
Inférieur : limite inférieure
Supérieur : limite supérieure
Numtrial : nombre d’essais n (entier, n \(≥\) 1)
pos : probabilité de succès p (0 \(≤\) p \(≤\) 1) -
Conditions de sortie
Prob : probabilité cumulée binomiale
Poisson PD (Densité de la loi de Poisson)
Calcule la probabilité dans une distribution de Poisson que le succès se produise lors d’un essai spécifié.
\(f(x)=\displaystyle\frac{e^{-\lambda} \lambda^x}{x!} \qquad (x=0,1,2,\cdots)\)
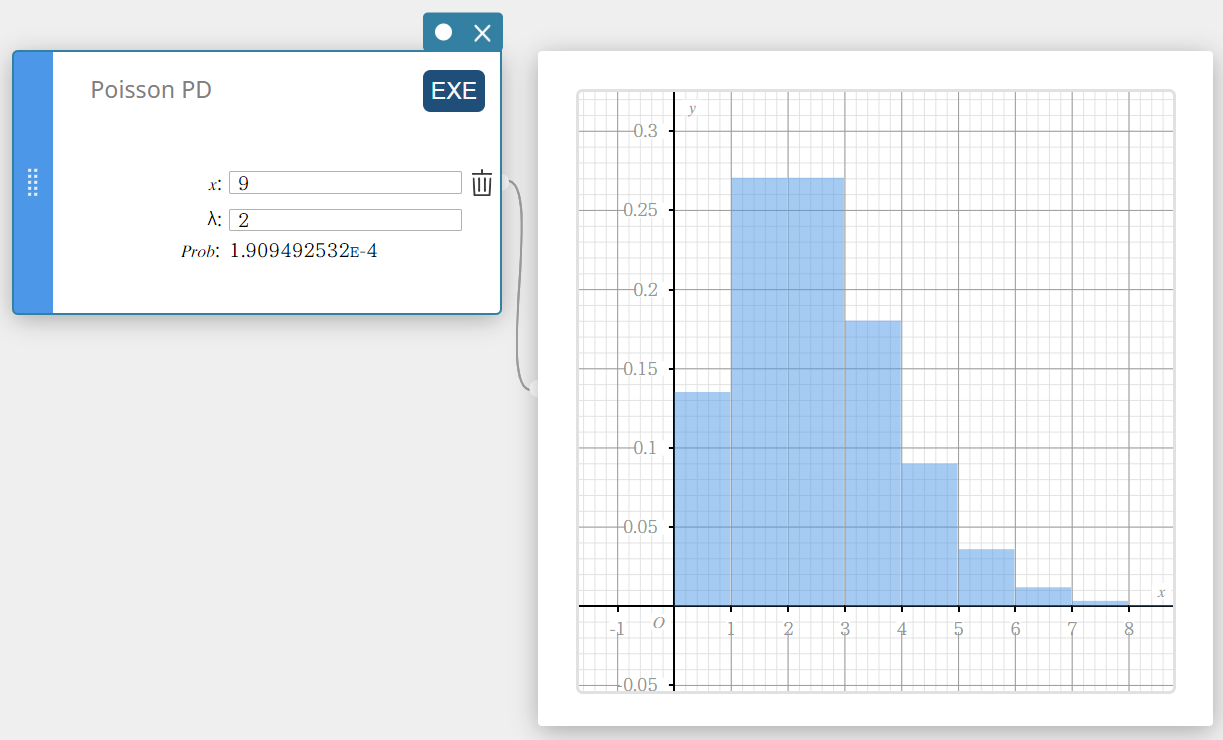
- Termes d’entrée
\( x \) : essai spécifié (entier, x \(≥\) 0)
\( \lambda \) : moyenne(\(\lambda \gt 0\)) -
Conditions de sortie
Prob : probabilité de poisson
Poisson CD (Fonction de répartition de la loi de Poisson)
Calcule la probabilité cumulée dans une distribution de Poisson que le succès se produise au moment ou avant un essai spécifié.
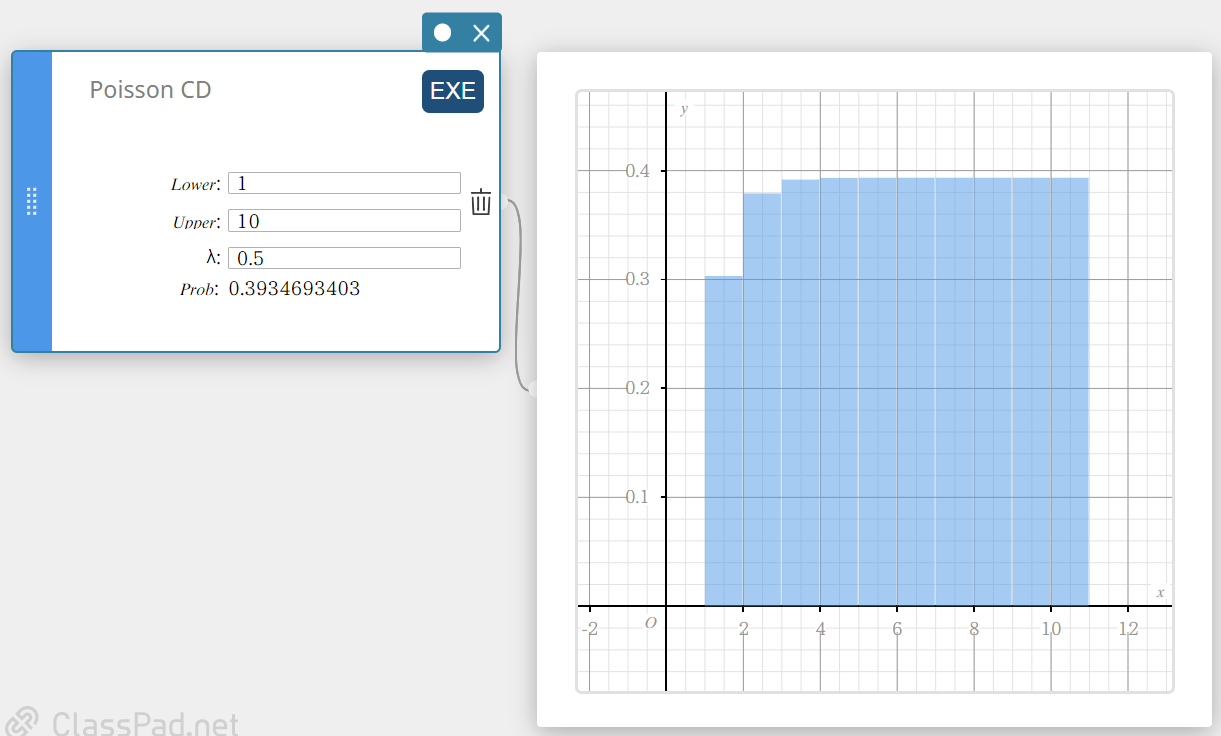
- Termes d’entrée
Inférieur : limite inférieure
Supérieur : limite supérieure
\( \lambda \) : moyenne(\(\lambda \gt 0\)) -
Conditions de sortie
Prob : probabilité cumulée de Poisson
Geometric PD (Densité de la loi Géométrique)
Calcule la probabilité, dans une distribution géométrique, que le succès se produise lors d’un essai spécifié.
\( f(x)=p(1-p)^{x-1} \qquad (x=1,2,3,\cdots) \)
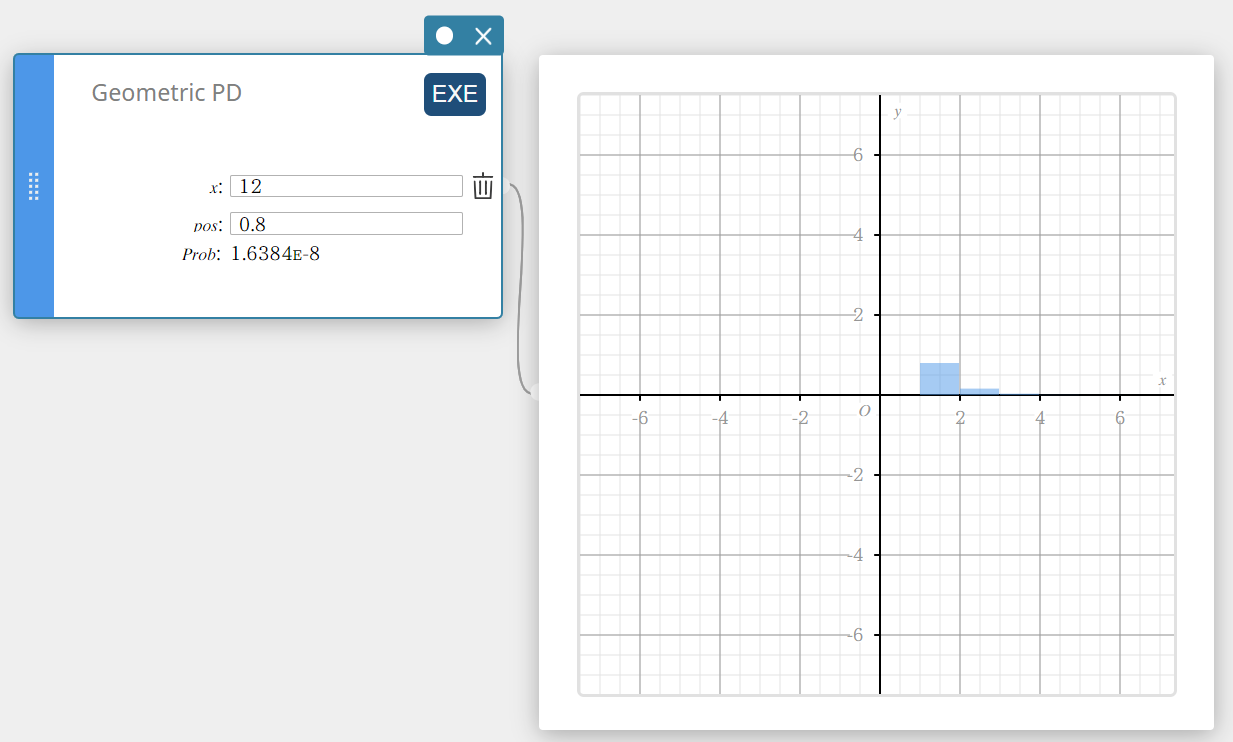
- Termes d’entrée
\( x \) : essai spécifié (entier positif)
pos : probabilité de succès p (0 \(≤\) p \(≤\) 1) -
Conditions de sortie
Prob : probabilité géométrique
Geometric CD (Fonction de répartition de la loi Géométrique)
Calcule la probabilité cumulée dans une distribution géométrique que le succès se produise au moment ou avant un essai spécifié.
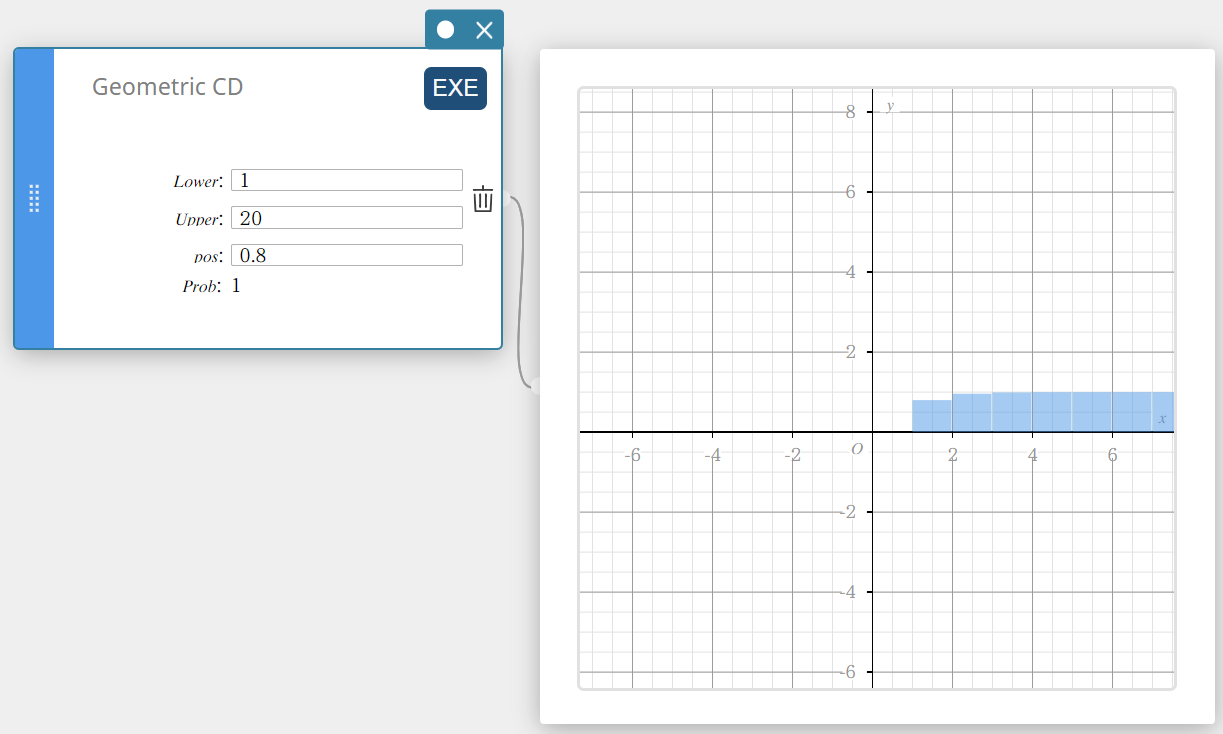
- Termes d’entrée
Inférieur : limite inférieure
Supérieur : limite supérieure
pos : probabilité de succès p (0 \(≤\) p \(≤\) 1) -
Conditions de sortie
Prob : probabilité géométrique cumulative
Hypergeometric PD (Densité de la loi Hypergéométrique)
Calcule la probabilité, dans une distribution hypergéométrique, que le succès se produise lors d’un essai spécifié.
\( prob = \displaystyle\frac{ {}_MC_x \times {}_{N-M}C_{n-x} }{ {}_NC_n } \)
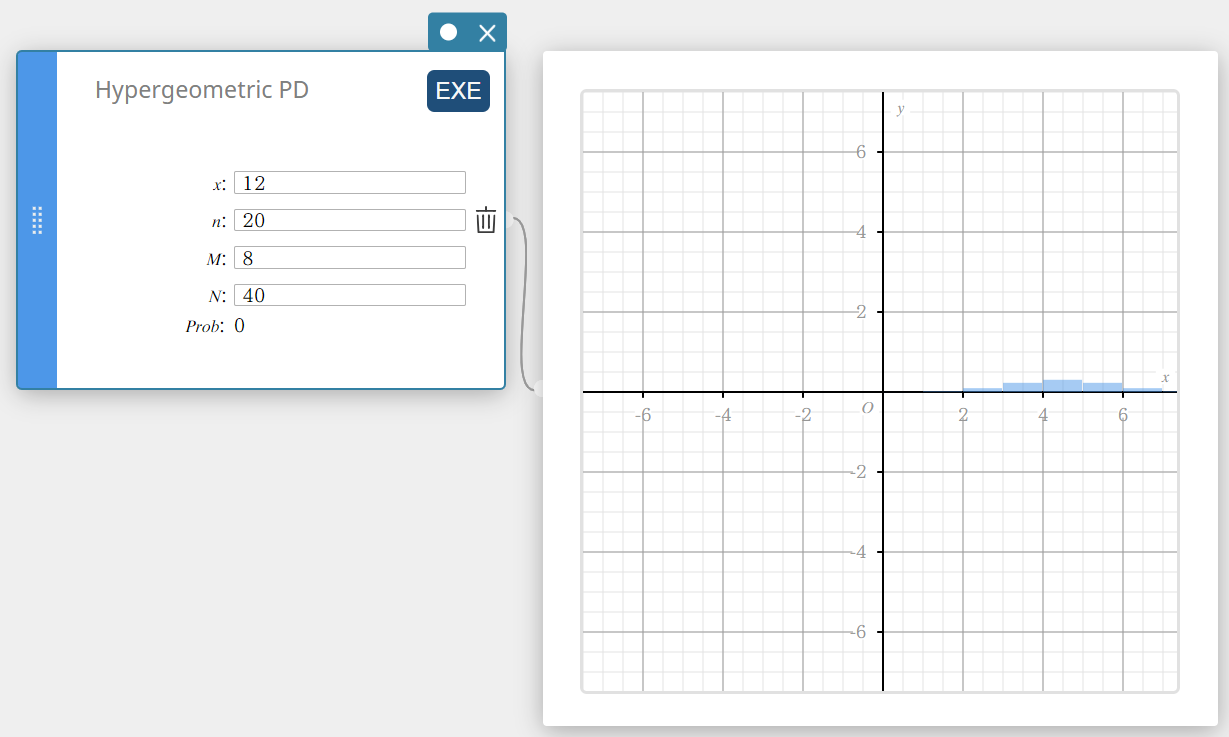
- Termes d’entrée
\(x\) : essai spécifié (entier)
\(n\) : nombre d’essais sur la population (0 \(≤\) n nombre entier)
\(M\) : number of successes in population (0 \(≤\) M entier)
\(N\) : taille de la population ( n \(≤\) N , M \(≤\) N entier) -
Conditions de sortie
Prob : probabilité hypergéométrique
Hypergeometric CD (Fonction de répartition de la loi Hypergéométrique)
Calcule la probabilité cumulée dans une distribution hypergéométrique que le succès se produise au moment ou avant un essai spécifié.
\( prob = \sum_{i=Lower}^{Upper}\displaystyle\frac{ {}_MC_i \times {}_{N-M}C_{n-i} }{ {}_NC_n } \)
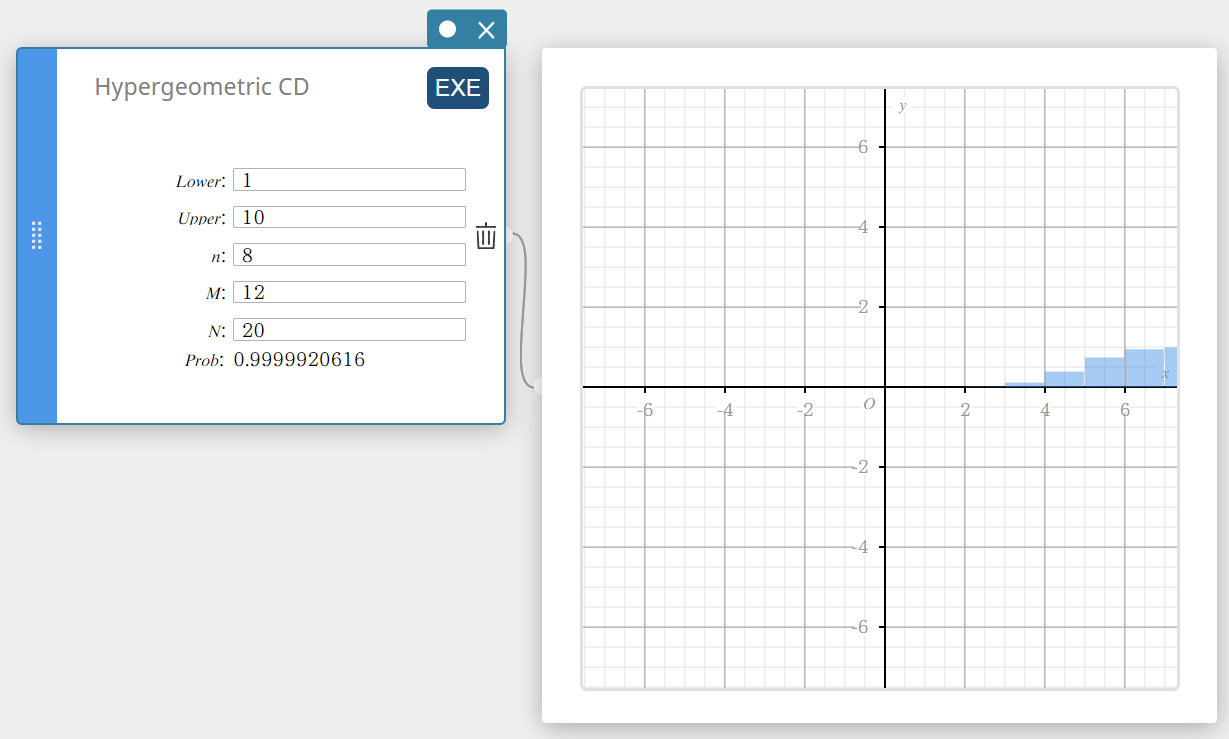
- Termes d’entrée
Inférieur : limite inférieure
Supérieur : limite supérieure
\(n\) : nombre d’essais sur la population (0 \(≤\) n nombre entier)
\(M\) : nombre de réussites dans la population (0 \(≤\) M entier)
\(N\) : taille de la population ( n \(≤\) N , M \(≤\) N entier) -
Conditions de sortie
Prob : probabilité cumulée hypergéométrique
Inverse Normal CD (Loi Normale inverse)
Calcule la ou les valeurs limites d’une distribution de probabilité cumulative normale pour les valeurs spécifiées.
Queue : gauche
\( \int_{-\infty}^{\alpha}f(x)dx=p \)
La limite supérieure α est renvoyée.
Queue : droite
\( \int_{\alpha}^{+\infty}f(x)dx=p \)
La limite inférieure α est renvoyée.
Queue : Centre
\( \int_{\alpha}^{\beta}f(x)dx=p \qquad \left( \mu=\displaystyle\frac{\alpha+\beta}{2} \right) \)
La limite inférieure α et la limite supérieure β sont renvoyées.
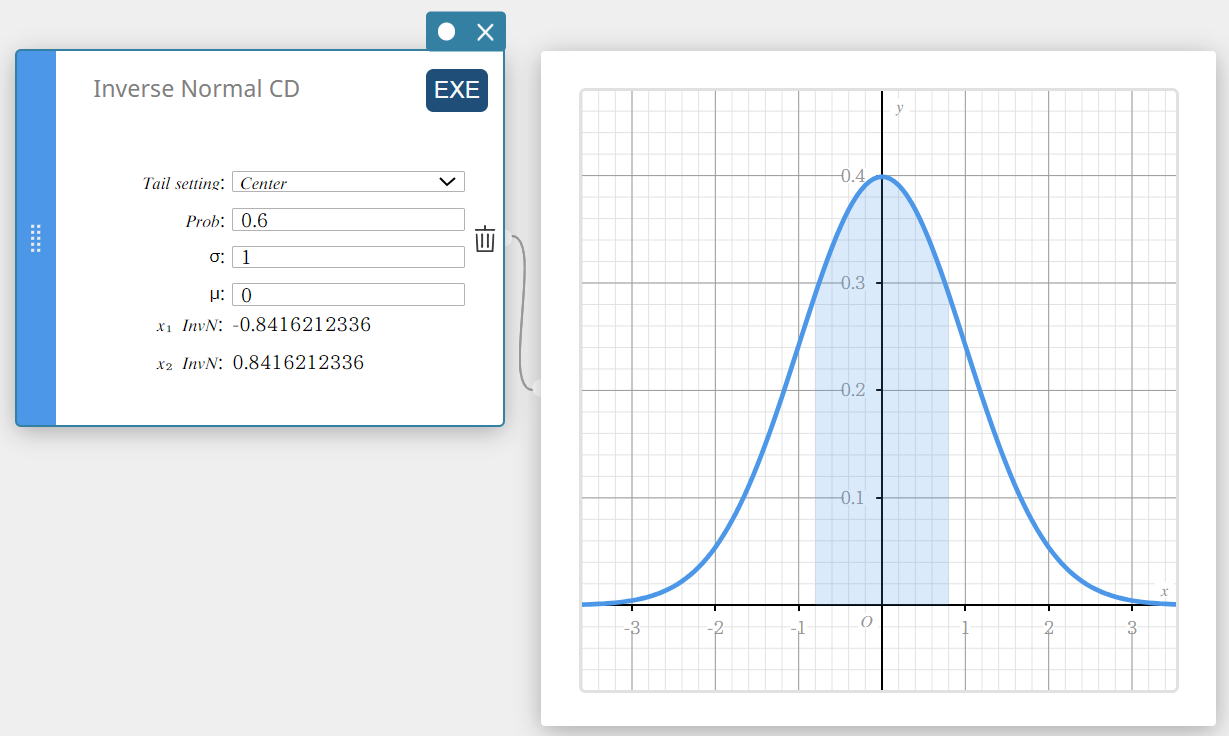
- Termes d’entrée
Réglage de la queue : spécification de la valeur de probabilité (Centre, Gauche, Droite)
Prob : valeur de probabilité (0 \(≤\) Aire \(≤\) 1)
\( \sigma \) : écart type de la population(\( \sigma > 0 \))
\( \mu \) : population signifie -
Conditions de sortie
\(x_1 {\rm InvN}\) : Limite supérieure lorsque Tail : gauche
Limite inférieure lorsque Tail : Right ou Tail : Center
\(x_2 {\rm InvN}\) : Limite supérieure lorsque Tail : Centre
Inverse t CD (Loi t de Student inverse)
Calcule la valeur limite inférieure de la distribution de probabilité cumulée t de Student pour les valeurs spécifiées.
\( \int_{\alpha}^{+\infty}f(x)=p \)
- Termes d’entrée
Prob : t probabilité cumulée (0 \(≤\) Aire \(≤\) 1)
\(df\) : degrés de liberté (df > 0) -
Conditions de sortie
xInv: La valeur limite inférieure de la distribution de probabilité cumulative t de Student
Inverse \(\chi^2\) CD (Loi du \(\chi^2\) inverse)
Calcule la valeur limite inférieure d’une distribution de probabilité cumulée \(\chi^2\) pour les valeurs spécifiées.
\( \int_{\alpha}^{+\infty}f(x)=p \)
- Termes d’entrée
Prob : \(\chi^2\) probabilité cumulée (0 \(≤\) Superficie \(≤\) 1)
\(df\) : degrés de liberté (entier positif) -
Conditions de sortie
\(x {\rm Inv}\) : La valeur limite inférieure d’une distribution de probabilité cumulative \(\chi^2\)
Inverse F CD (Loi F inverse)
Calcule la valeur limite inférieure d’une distribution de probabilité cumulée F pour les valeurs spécifiées.
\( \int_{\alpha}^{+\infty}f(x)=p \)
- Termes d’entrée
Prob : F probabilité cumulée (0 \(≤\) Aire \(≤\) 1)
\(n:df\) : degrés de liberté du numérateur (entier positif)
\(d:df\) : degrés de liberté du dénominateur (entier positif) -
Conditions de sortie
xInv: La valeur limite inférieure d’une distribution de probabilité cumulative F
Inverse Binomial CD (Loi Binomiale inverse)
Calcule le nombre minimum d’essais d’une distribution de probabilité cumulée binomiale pour des valeurs spécifiées.
\( \sum_{x=0}^{m}f(x)\ge prob \)
- Termes d’entrée
Prob : probabilité cumulée binomiale(\(0 \le\) Zone \(\le 1\))
Numtrial : nombre d’essais n (entier, n \(≥\) 0)
pos : probabilité de succès p (0 \(≤\) p \(≤\) 1) -
Conditions de sortie
xInv : La valeur limite inférieure d’une distribution de probabilité cumulative F
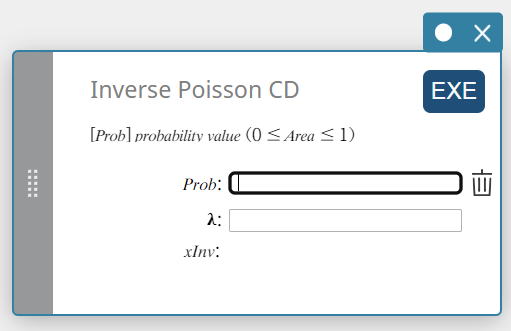
Inverse Poisson CD (Loi de Poisson inverse)
Calcule le nombre minimum d’essais d’une distribution de probabilité cumulative de Poisson pour des valeurs spécifiées.
\( \sum_{x=0}^{m}f(x)\ge prob \)
- Termes d’entrée
Prob : probabilité cumulée de Poisson(\(0 \le\) Zone \(\le 1\))
\( \lambda \) : moyenne(\(\lambda \gt 0\)) -
Conditions de sortie
xInv : Le nombre minimum d’essais (la valeur limite supérieure) d’une distribution de probabilité cumulative de Poisson
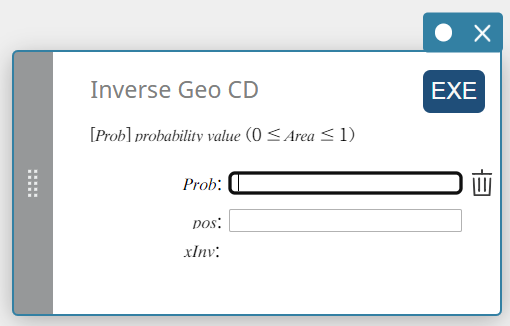
Inverse Geo CD (Loi Géométrique inverse)
Calcule le nombre minimum d’essais d’une distribution de probabilité cumulée géométrique pour des valeurs spécifiées.
\( \sum_{x=0}^{m}f(x)\ge prob \)
- Termes d’entrée
Prob : probabilité cumulée géométrique(\(0 \le\) Zone \(\le 1\))
pos : probabilité de succès p(\(0 \le p \le 1\)) -
Conditions de sortie
xInv : Le nombre minimum d’essais (la valeur limite supérieure) d’une distribution de probabilité cumulative géométrique
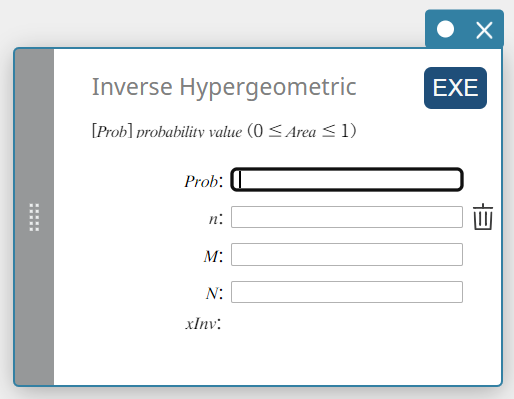
Inverse Hypergeometric (Loi Hypergéométrique inverse)
Calcule le nombre minimum d’essais d’une distribution de probabilité cumulée hypergéométrique pour des valeurs spécifiées.
\( prob \le \sum_{i=0}^{X} \displaystyle\frac{ {}_MC_i \times {}_{N-M}C_{n-i} }{ {}_NC_n } \)
- Termes d’entrée
Prob : probabilité cumulée hypergéométrique(\(0 \le\) Aire \(\le 1\))
\(n\) : nombre d’essais sur la population (0 \(≤\) n nombre entier)
\(M\) : nombre de réussites dans la population (0 \(≤\) M entier)
\(N\) : taille de la population ( n \(≤\) N , M \(≤\) N entier) -
Conditions de sortie
xInv: Le nombre minimum d’essais (la valeur limite supérieure) d’une distribution de probabilité cumulée hypergéométrique
Autres graphiques statistiques
Nuage de points
Ce graphique compare le ratio accumulé de données avec un ratio accumulé de distribution normale. Si le nuage de points est proche d’une ligne droite, alors les données sont à peu près normales. Un écart par rapport à la ligne droite indique un écart par rapport à la normalité.
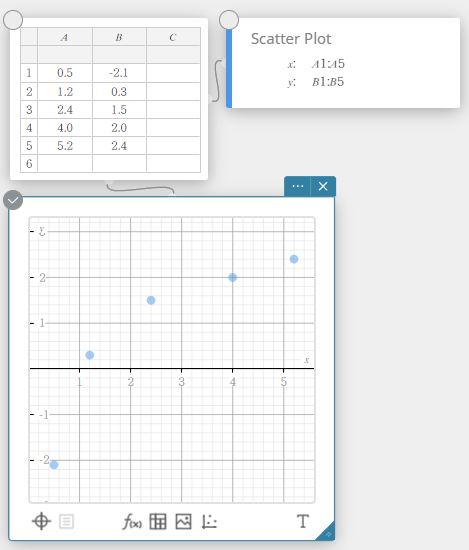
Diagramme en boîte et moustaches
Ce type de graphique vous permet de voir comment un grand nombre d’éléments de données sont regroupés dans des plages spécifiques. Une case renferme toutes les données d’une zone allant du premier quartile (\({\rm Q}_1\)) au troisième quartile (\({\rm Q}_3\)), avec une ligne tracée à la médiane (\({\rm Med}\)). Des lignes (appelées moustaches) s’étendent de chaque extrémité de la boîte jusqu’au minimum (\({\rm minX}\)) et le maximum (\({\rm maxX}\)) des données.
Histogramme
Un histogramme montre la fréquence (distribution des fréquences) de chaque classe de données sous forme de barre rectangulaire.Les classes sont sur l’axe horizontal, tandis que la fréquence est sur l’axe vertical. Si nécessaire, vous pouvez modifier la valeur de départ (\(HStart\)) et la valeur de pas (\(HStep\)) de l’histogramme.
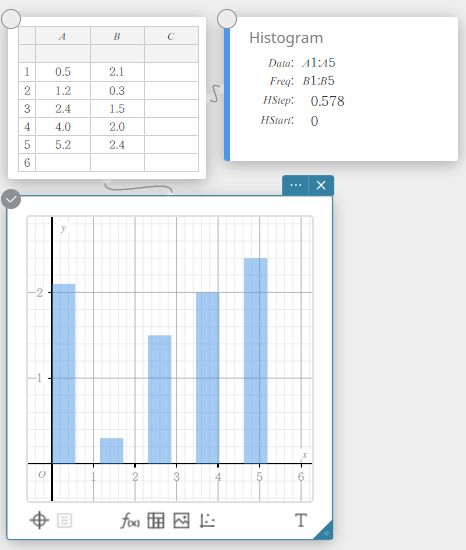
Diagramme circulaire
Vous pouvez dessiner un graphique circulaire basé sur les données d’une liste spécifique.
Tracé de points
Les valeurs de la colonne A (axe horizontal) représentent les numéros de compartiment, tandis que les valeurs de la colonne B (axe vertical) représentent le nombre de points de données dans chaque compartiment. Un point est tracé pour chaque point de données dans un bac.